ImageNet Classification with Deep Convolutional Neural Networks
저자: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
발행년도: 2012년
인용수: 160000회
논문 링크: https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
1. TL;DR
AlexNet은 “특징을 어떻게 설계할지”가 아니라 “대규모 데이터와 연산이 주어졌을 때도 표현을 끝까지 학습으로 밀어붙일 수 있는가”를 문제로 다시 세웠다.
그 과정에서 ‘딥러닝은 비현실적이다’라는 당시의 암묵적 전제를, GPU·ReLU·정규화·드롭아웃 같은 실용적 선택으로 흔들어 놓았다.
그래서 이 논문은 성능 향상이 아니라, 컴퓨터 비전에서 문제를 푸는 기본 단위를 “수작업 파이프라인”에서 “학습 가능한 시스템”으로 옮겨 놓았다고 보이기 시작했다.
2. 이 논문을 읽기 전의 문제 인식
이미지 인식은 특징 설계의 문제라고 생각했었다. 그 다음이 분류기라고 이해했었다. 좋은 특징을 만들면, 분류기는 비교적 단순해도 된다고 여겼다.
왜 자연스러웠냐면, 당시의 성공 사례들이 그랬기 때문이다. SIFT나 HOG 같은 기술은 “사람이 아는 불변성”을 코드로 박아 넣는 방식이었고, 그게 데이터가 많지 않은 현실에서 합리적으로 보였기 때문이다. 학습은 마지막 얇은 층에서만 일어나도 충분하다고 느꼈다.
딥한 신경망은 가능성은 있지만 실용적이지 않다고 생각했었다. 데이터가 부족하고, 학습이 느리고, 과적합이 심하다고 배웠기 때문이다. 이 전제는 질문이 되지 않았다. “좋은 특징을 어떻게 만들까”는 질문이었지만, “특징을 만들지 말고 학습시키면 안 되나”는 현실적으로 성립하지 않는 질문처럼 취급했었다.
3. 읽다가 멈칫했던 지점
이 논문은 문제를 ‘인식’으로 말하면서, 실제로는 ‘학습 가능성’ 자체를 다루고 있다고 느꼈다. 성능표보다 먼저 눈에 들어온 건, 그들이 왜 이런 선택을 했는지에 대한 집요한 실무적 설명이었다. GPU를 썼다, ReLU를 썼다, 데이터 증강을 했다 같은 문장들이 “기술 자랑”이 아니라 “딥 모델이 가능한 조건”을 조립하는 느낌으로 읽혔다.
처음 의문은 여기서 생겼다. “왜 굳이 이렇게까지 해서 큰 네트워크를 학습시키려 했지?”라는 질문이 생겼다. 단순히 더 좋은 분류기를 원했다면 더 얕고 안정적인 방법도 많았기 때문이다. 그런데 저자들은 안정성을 택하지 않았다. 그들은 ‘표현을 사람이 만들지 않는’ 방향을 끝까지 밀었다. 그 순간 문제 정의가 바뀌어 보이기 시작했다.
4. 저자들이 다시 정의한 ‘문제’
AlexNet이 다시 세운 문제는 “이미지에서 유용한 특징을 어떻게 설계할까”가 아니었다. “대규모 자연 이미지 분류에서, 특징 추출부터 분류까지를 하나의 학습 문제로 만들 수 있는가”였다.
기존 정의와의 차이는 방법이 아니라 관점이었다. 기존은 파이프라인을 전제로 했다. 특징은 사람이 만든다, 학습은 그 위에서 작게 한다, 계산은 제한적이다 같은 전제가 붙어 있었다. AlexNet은 그 전제를 떼어냈다. 표현 학습을 ‘가능하게 만드는 조건’을 문제의 중심으로 끌어올렸다.
즉, 이 논문은 정확도를 올리는 논문이라기보다 “끝까지 학습으로 가는 것이 현실적인가”를 증명하려는 논문으로 읽혔다.
5. 왜 기존 문제 정의로는 한계가 있었는가
기존 연구가 깔고 있던 가정은 “사람이 설계한 특징이 일반화의 핵심”이라는 믿음이었다. 이 가정은 데이터가 작고 계산이 제한적일 때는 합리적이었다. 하지만 ImageNet 같은 규모가 등장하면서 그 합리성이 흔들렸다고 보였다. 데이터가 많아지면, 사람이 만든 불변성보다 데이터에서 드러나는 변이를 그대로 흡수하는 쪽이 더 강해질 수 있기 때문이다.
그 가정이 만든 구조적 한계는 확장성에서 나타났다고 느꼈다. 카테고리가 늘어나고, 배경과 조명과 포즈가 폭발적으로 다양해질수록, 특징 설계는 끝없는 땜질이 되기 쉽다. 반면 학습 기반 표현은 “더 큰 데이터”를 연료로 삼을 수 있다. 기존 정의는 그 연료를 제대로 쓰지 못하게 만들었다.
성능의 한계만이 아니었다. 개발 방식의 한계도 있었다. 특징을 바꾸면 전체 파이프라인이 다시 설계되고, 어떤 요소가 기여했는지 해석도 복잡해졌다. AlexNet은 이 복잡함을 “학습이라는 하나의 최적화 문제”로 밀어 넣으려 했다. 그게 이 논문의 문제의식처럼 보였다.
6. 방법 개요 — 문제 정의의 결과물
6.1 전체 접근
이 문제 정의라면, 큰 신경망을 학습시키는 쪽으로 갈 수밖에 없었다. “표현을 학습시키겠다”를 말로만 하면 공허하다. 그래서 저자들은 학습을 가능하게 하는 현실적 병목을 하나씩 제거하는 방식으로 접근을 구성했다. 계산 병목은 GPU로, 최적화 병목은 ReLU로, 데이터 부족은 증강으로, 일반화 병목은 드롭아웃으로 대응했다.
여기서 중요한 건, 이 선택들이 ‘정답 기술’이라서가 아니라 ‘문제 정의의 필연’처럼 배치됐다는 점이었다. 표현을 학습시키겠다고 선언하는 순간, 학습이 안 되는 이유들을 기술적으로 해결해야 했기 때문이다.

6.2 핵심 구성 요소
ReLU는 “깊은 모델은 학습이 느리다”라는 전제를 깨기 위한 선택으로 보였다. 시그모이드류의 포화 문제를 피해서, 큰 모델을 “학습 가능한 대상”으로 바꿔 놓는 역할을 했다.
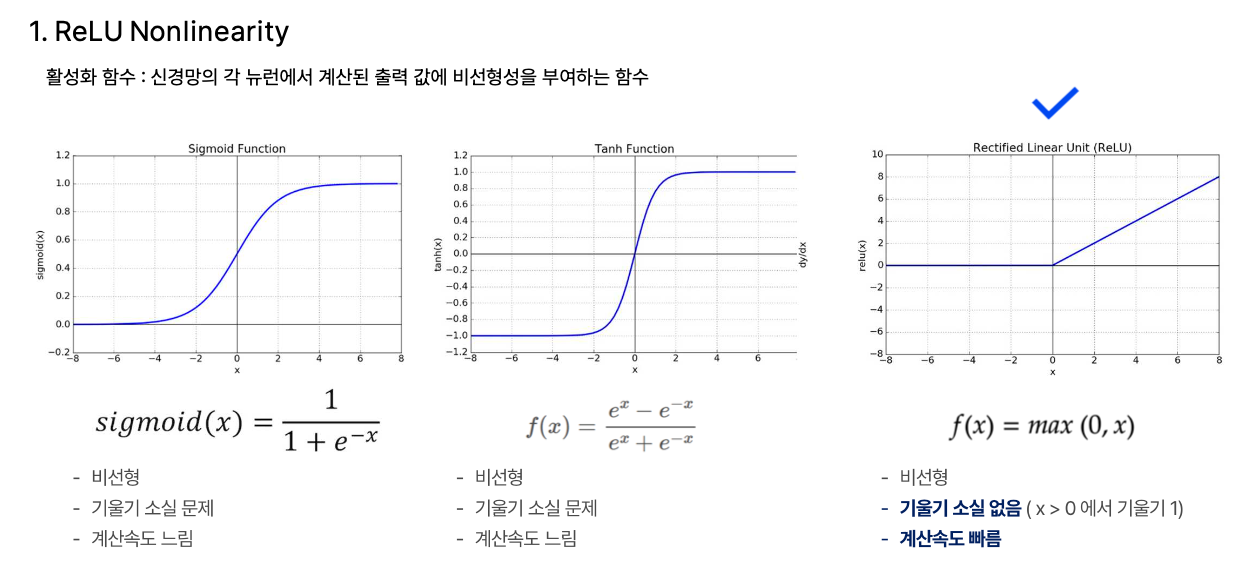

GPU 학습은 단순 가속이 아니었다. ‘딥러닝은 계산이 너무 든다’는 반박을 무력화하는 장치였다. 논문이 모델을 2개 GPU로 쪼갰다는 사실은, 그들이 이 문제를 이론이 아니라 현실의 제약으로 보고 있었다는 신호로 읽혔다.





7. 실험 결과를 다시 보는 관점
이 실험은 단순히 “우리가 1등 했다”를 보여주려는 것처럼 보이지 않았다. “이렇게 큰 네트워크가 실제로 대규모 데이터에서 학습되고, 기존 파이프라인을 넘어설 만큼 일반화한다”를 설득하려는 설계로 읽혔다.
그래서 결과에서 더 중요한 건 숫자 자체보다 메시지였다. 수작업 특징 기반 시스템이 지배하던 벤치마크에서, end-to-end 학습이 승리할 수 있다는 사실이 문제 정의를 정당화했다. “특징 설계가 본질”이라는 인식이 흔들리는 순간이었다.
8. Ablation이 드러내는 핵심 가정
저자들이 중요하다고 주장한 요소는 “큰 모델 + 학습을 가능하게 하는 장치들”의 결합이었다. 하나만으로는 설득력이 약했다. GPU만 있어도 과적합하면 끝이고, 드롭아웃만 있어도 학습이 느리면 끝이고, ReLU만 있어도 데이터가 부족하면 끝이었다.
제거했을 때 무너지는 것은 성능만이 아니었다. “딥 모델은 실용적이다”라는 주장 자체가 약해졌다. 즉, 이 논문이 의존한 핵심 가정은 “대규모 데이터가 존재하고, 계산을 동원할 수 있으며, 그 위에서 정규화·증강 같은 장치로 일반화를 확보할 수 있다”는 조건이었다. 그 조건이 만족될 때, 특징 설계의 필요성이 줄어든다는 가정이었다.
9. 여전히 남는 질문
이 문제 정의는 데이터와 계산이 부족한 환경을 직접 해결하지 못했다고 느꼈다. “학습으로 가자”는 방향은 제시했지만, 그 방향이 모든 현장에 즉시 적용되는 건 아니었다.
또 하나의 질문은 해석 가능성이었다. 수작업 특징은 실패해도 이유를 말할 수 있었지만, 학습된 표현은 이유를 말하기 어려웠다. 이 논문은 그 비용을 감수하고 성능과 확장성을 택했다. 그 선택이 이후 연구에서 설명가능성, 안정성, 편향 같은 문제로 다시 돌아오게 됐다고 보였다.
마지막으로, ‘더 크면 더 좋다’로 읽힐 위험도 있었다. 이 논문이 바꾼 건 스케일의 가능성이었지만, 스케일이 곧바로 원리의 설명이 되지는 않았다. 그래서 후속 연구가 구조적 아이디어와 학습 안정성을 계속 파고들 수밖에 없었다고 느꼈다.
10. 정리
이 논문은 “이미지 인식은 사람이 특징을 만드는 문제”를 문제로 정의했고, 그 정의는 컴퓨터 비전에서 문제를 바라보는 방식을 “수작업 설계”에서 “대규모 학습 시스템”으로 바꿔 놓았다고 정리했다.
'PaperReview' 카테고리의 다른 글
| [FastReID]FastReID: A Pytorch Toolbox for General Instance Re-identification (0) | 2026.01.07 |
|---|---|
| [DDPM]Denoising Diffusion Probabilistic Models (0) | 2026.01.07 |
| Visual Prompt Tuning (0) | 2026.01.06 |
| [ResNet] Deep Residual Learning for Image Recognition (1) | 2026.01.04 |
| [Deit] Deit: Training data-efficient image transformers & distillation through attention (0) | 2025.12.27 |