Simple Online and Realtime Tracking
저자: Alex Bewley, Zongyuan Ge, Lionel Ott
발행년도: 2016년
인용수: 3500회
논문 링크: https://arxiv.org/abs/1602.00763
arXiv ID: 1602.00763
SORT: 실시간 다중 객체 추적의 간결한 접근법
문제 정의 (Problem Definition)
다중 객체 추적(Multiple Object Tracking, MOT)은 비디오에서 여러 객체를 동시에 감지하고 추적하는 문제를 다룬다. 자율주행, 감시 시스템, 스포츠 분석 등 다양한 분야에서 핵심 기술로 활용되지만, 실시간 처리와 정확도를 동시에 달성하기는 여전히 어려운 과제였다.
2016년 당시 대부분의 MOT 시스템은 복잡한 appearance model과 sophisticated한 data association 기법에 의존했다. 이런 방법들은 높은 정확도를 보였지만, 계산 복잡도가 높아 실시간 처리가 불가능했다. 반면 간단한 방법들은 속도는 빠르지만 occlusion이나 ID switching 문제에 취약했다.
실제 환경에서는 조명 변화, 부분적 가림(occlusion), 유사한 외형의 객체 등 다양한 어려움이 존재한다. 특히 보행자 추적 시나리오에서는 수십 명이 동시에 움직이며 서로를 가리는 상황이 빈번하게 발생한다. 이런 복잡한 상황에서도 각 객체의 ID를 일관성 있게 유지하면서 실시간으로 처리해야 하는 것이 핵심 도전 과제였다.
기존 방법의 한계 (Motivation)
당시 주류였던 접근 방식은 크게 세 가지로 나눌 수 있었다. 첫째, appearance feature 기반 방법은 각 객체의 시각적 특징을 학습해 매칭하는 방식이었다. 색상 히스토그램, HOG, deep feature 등을 활용했지만, 계산량이 많고 유사한 외형의 객체를 구분하기 어려웠다.
둘째, graph-based optimization 방법은 전체 시퀀스를 하나의 최적화 문제로 모델링했다. Network flow나 multi-commodity flow 같은 기법으로 global optimal solution을 찾았지만, batch processing이 필요해 실시간 처리가 불가능했다. 또한 시퀀스가 길어질수록 계산 복잡도가 기하급수적으로 증가했다.
셋째, probabilistic 방법들은 Particle Filter나 Multiple Hypothesis Tracking(MHT)을 사용했다. 이론적으로는 우수했지만, 추적 대상이 많아지면 hypothesis가 폭발적으로 증가하는 문제가 있었다. pruning을 통해 복잡도를 줄이려 했지만, 이 과정에서 정보 손실이 발생했다.
출처: Google Images
![]()
출처: Google Images
기존 방법들의 공통적인 문제는 "복잡도와 성능의 trade-off"였다. 저자들은 이 지점에서 발상의 전환을 시도했다. 정말 복잡한 모델이 필요한가? 단순한 motion model만으로도 충분하지 않을까?
제안 방법의 핵심 아이디어 (Key Idea)
SORT의 핵심 아이디어는 "대부분의 실제 상황에서 객체의 움직임은 단순한 선형 모델로 충분히 예측 가능하다"는 관찰에서 출발했다. 복잡한 appearance model 대신 Kalman Filter와 Hungarian algorithm만을 사용해 추적을 수행한다.
이를 일상적인 예시로 설명하면, 보행자가 횡단보도를 건널 때 대부분 일정한 속도로 직진한다. 급격한 방향 전환이나 속도 변화는 드물다. 이런 규칙적인 움직임 패턴을 활용하면, 복잡한 외형 정보 없이도 다음 위치를 예측할 수 있다.
기존 방법들이 "누가 누구인지" 구분하는 데 집중했다면, SORT는 "어디로 움직일지" 예측하는 데 집중했다. 이는 문제의 복잡도를 크게 낮추면서도 실용적인 성능을 달성할 수 있게 했다. 특히 detection 성능이 좋은 최신 detector와 결합했을 때, 이런 단순한 접근법도 충분히 경쟁력 있음을 보였다.
![]()
출처: Google Images
아키텍처 설명 (Architecture)
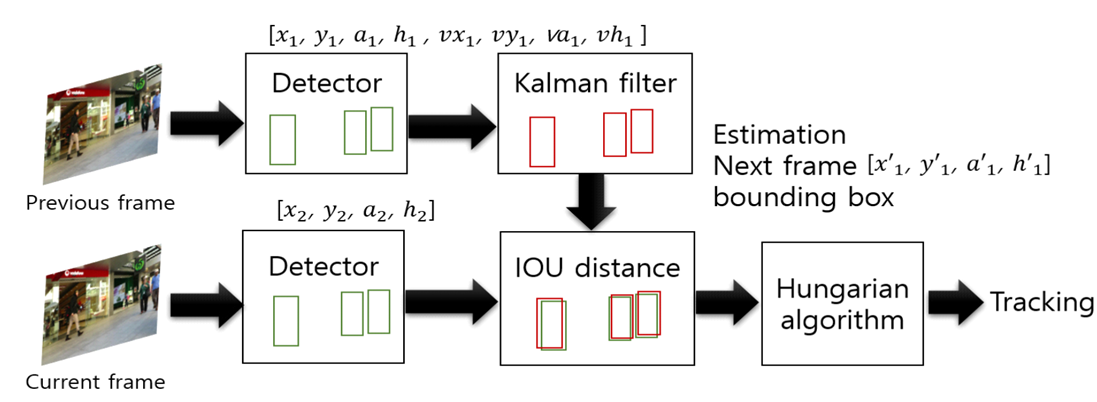
SORT의 전체 파이프라인은 네 단계로 구성된다. 먼저 각 프레임에서 객체를 검출하고, 기존 track과의 연관성을 계산한 뒤, 매칭을 수행하고 track을 업데이트한다.
Detection 단계에서는 Faster R-CNN 같은 기성 detector를 사용한다. 각 detection은 bounding box 좌표 [x, y, w, h]와 confidence score를 포함한다. 저자들은 detector 자체를 개선하지 않고, 기존 방법을 그대로 활용했다.
Prediction 단계에서는 각 track의 Kalman Filter가 다음 위치를 예측한다. 상태 벡터는 [x, y, s, r, ẋ, ẏ, ṡ]로 정의되며, 여기서 s는 scale(면적), r은 aspect ratio다. constant velocity model을 가정해 선형 움직임을 모델링한다.
Association 단계는 IoU(Intersection over Union) 거리를 사용한다. 예측된 bounding box와 detection 간의 IoU를 계산해 cost matrix를 만들고, Hungarian algorithm으로 optimal assignment를 찾는다. IoU가 임계값 이하인 매칭은 거부된다.
# Simplified SORT pipeline
for frame in video:
detections = detector(frame)
# Predict next positions
for track in tracks:
track.predict()
# Associate predictions with detections
matches, unmatched_dets, unmatched_trks = \
associate(detections, tracks, iou_threshold=0.3)
# Update matched tracks
for m in matches:
tracks[m[1]].update(detections[m[0]])
# Create new tracks
for i in unmatched_dets:
tracks.append(create_track(detections[i]))Track Management에서는 track의 생성과 소멸을 관리한다. 새로운 detection은 즉시 track이 되지 않고, 연속된 프레임에서 검출되어야 확정된다. 반대로 일정 프레임 동안 매칭되지 않은 track은 삭제된다.
접근 방법의 특징 및 설계 의도 (Design Choices)
SORT의 설계 철학은 "simplicity first"다. 복잡한 요소를 배제하고 essential component만 남겼다. 이런 선택의 배경에는 몇 가지 중요한 관찰이 있었다.
첫째, appearance feature를 완전히 배제했다. 저자들은 good detector가 주어진다면 motion information만으로도 충분하다고 판단했다. 이는 계산량을 극적으로 줄이면서도, 조명 변화나 부분적 가림에 robust한 특성을 보였다.
둘째, IoU 기반 매칭을 선택했다. 유클리디안 거리나 Mahalanobis 거리 대신 IoU를 사용한 이유는 scale 변화에 자연스럽게 대응하기 위함이었다. 카메라에 가까워지는 객체는 크기가 커지는데, IoU는 이런 변화를 자연스럽게 처리한다.
셋째, track 생성에 conservative한 정책을 적용했다. false positive를 줄이기 위해 최소 3프레임 연속 검출을 요구했다. 이는 detector의 occasional false alarm을 효과적으로 필터링했다.
하지만 이런 설계 선택들이 모두 ablation study로 검증되지는 않았다. 특히 IoU threshold나 track 생성/삭제 기준값들은 경험적으로 설정된 것으로 보인다. 더 체계적인 hyperparameter 분석이 필요했을 것 같다.
실험 결과 분석
저자들은 MOT Challenge 2015 벤치마크에서 실험을 수행했다. SORT는 260 FPS라는 압도적인 속도를 달성하면서도, MOTA(Multiple Object Tracking Accuracy) 측면에서 경쟁력 있는 성능을 보였다.
흥미로운 점은 SORT가 특히 fragmentation이 적다는 것이다. 즉, track이 중간에 끊어지는 현상이 적었다. 이는 motion model의 연속성이 appearance 변화보다 더 안정적임을 시사한다. 반면 ID switch는 상대적으로 많았는데, 이는 appearance 정보 부재의 직접적인 결과였다.
Detection 품질과의 상관관계 분석도 주목할 만하다. 저자들은 public detection과 private detection을 모두 실험했는데, better detector를 사용할수록 SORT의 성능 향상 폭이 더 컸다. 이는 SORT가 detection에 크게 의존한다는 비판을 받을 수 있지만, 동시에 detector 발전의 혜택을 직접적으로 받는다는 장점도 된다.
실험 설계에서 아쉬운 점은 다양한 시나리오에 대한 분석이 부족하다는 것이다. 특히 dense crowd, severe occlusion, 급격한 motion 변화 같은 challenging case에서의 성능 분석이 없다. 또한 다른 간단한 baseline(예: nearest neighbor matching)과의 비교도 있었다면 좋았을 것이다.
총평: 개인적 해석과 후속 연구 방향
SORT는 "복잡함이 항상 좋은 것은 아니다"라는 중요한 메시지를 전달했다. 문제의 본질을 파악하고 불필요한 복잡도를 제거함으로써, 실용적인 해결책을 제시했다. 이는 단순히 속도만 빠른 방법이 아니라, engineering과 research의 균형을 보여주는 좋은 예시다.
실무 적용 관점에서 SORT의 장점은 명확하다. 구현이 간단하고, 디버깅이 쉽고, 예측 가능한 동작을 한다. 계산 자원이 제한된 edge device에서도 충분히 동작 가능하다. 다만 crowded scene이나 similar appearance objects가 많은 경우에는 성능이 급격히 떨어질 수 있다.
이 연구를 발전시킨다면 몇 가지 방향을 고려해볼 수 있다. 첫째, adaptive motion model을 도입해 객체별로 다른 움직임 패턴을 학습할 수 있을 것이다. 둘째, minimal appearance feature를 선택적으로 활용해 ID switch를 줄일 수 있을 것이다. 예를 들어, re-identification이 필요한 순간에만 appearance를 사용하는 hybrid approach가 가능하다.
셋째, uncertainty estimation을 통해 더 robust한 tracking을 구현할 수 있다. Kalman Filter의 covariance를 활용해 예측 불확실성이 높은 경우에만 추가 정보를 사용하는 방식이다. 마지막으로, 최근의 transformer 기반 detector와의 조합을 실험해보고 싶다. attention mechanism이 제공하는 global context가 SORT의 local motion model을 보완할 수 있을 것으로 기대된다.
SORT의 진정한 기여는 "baseline의 재정의"에 있다고 생각한다. 이후 많은 연구들이 SORT를 baseline으로 사용하며, 여기에 점진적 개선을 더하는 방식으로 발전했다. Deep SORT, SORT-OH 등이 그 예시다. 때로는 복잡한 해결책보다 simple but strong baseline이 분야 발전에 더 큰 기여를 할 수 있음을 보여준 연구다.
'PaperReview' 카테고리의 다른 글
| [철학] The case for motivated reasoning (0) | 2026.01.25 |
|---|---|
| [DeepSORT] Simple Online and Realtime Tracking with a Deep Association Metric (1) | 2026.01.25 |
| [CVEP] CogVLM: Visual Expert for Pretrained Language Models (0) | 2026.01.25 |
| [SLIP] SLIP: Self-supervision meets Language-Image Pre-training (0) | 2026.01.25 |
| [TTRR] TextVQA: Towards Reading and Reasoning on Text in Images (0) | 2026.01.25 |