XGBoost: A Scalable Tree Boosting System
저자: Tianqi Chen, Carlos Guestrin
발행년도: 2016년
인용수: None회
논문 링크: http://arxiv.org/abs/1603.02754v3
arXiv ID: 1603.02754
XGBoost 논문을 제대로 파헤쳐봤다 — 알고리즘과 시스템 설계의 결합
Kaggle 대회를 둘러보면 빠지지 않는 이름이 있었다. XGBoost. 2015년 Kaggle 블로그에 소개된 29개 우승 솔루션 중 17개가 XGBoost를 사용했다고 했다. 딥러닝이 11개였던 것과 비교하면 압도적이었다. 단순히 "잘 되는 부스팅 라이브러리" 정도로만 알고 있었는데, 도대체 왜 이렇게까지 많이 쓰이는 건지 궁금해졌다. 그래서 원논문을 펼쳤다.
읽어보니 이 논문은 단순한 알고리즘 제안이 아니었다. 알고리즘 혁신과 시스템 엔지니어링을 동시에 다룬 논문이었다. 그래서 정리가 좀 길어질 수 있는데, 핵심만 추려봤다.
기존 방법의 한계, 그리고 XGBoost가 풀려는 문제
Gradient tree boosting 자체는 이미 Friedman이 2001년에 제안한 방법이었다. scikit-learn이나 R의 gbm 패키지로도 쓸 수 있었다. 그런데 문제는 확장성(scalability)이었다.
데이터가 수억 건을 넘어가면 기존 구현체들은 속수무책이었다. 메모리에 다 안 올라가는 데이터는 처리할 수 없었고, 희소(sparse) 데이터에 대한 특별한 처리도 없었다. 분산 환경에서의 학습도 제한적이었다. 결국 "좋은 알고리즘인 건 알겠는데, 현실 데이터에 적용하기 어렵다"는 상황이었다.
XGBoost의 핵심 가치는 "트리 부스팅을 수십억 건 규모까지 확장 가능하게 만든 end-to-end 시스템"이라는 점이었다.
정규화된 목적함수 — 출발점부터 다르다
XGBoost의 알고리즘적 기반은 기존 gradient boosting과 크게 다르지 않았다. 트리를 하나씩 추가하면서 잔차를 줄여가는 additive training 방식이었다. 하지만 정규화(regularization)를 목적함수 자체에 녹여넣은 점이 달랐다.
목적함수에 트리의 리프 수 T와 리프 가중치 w의 L2 노름을 페널티로 추가했다. 이건 단순히 과적합을 방지하는 수준이 아니라, 트리 구조의 복잡도 자체를 학습 과정에서 제어하겠다는 의도였다. 정규화 파라미터를 0으로 두면 기존 gradient tree boosting과 동일해지니, 기존 방법의 일반화라고 볼 수 있었다.
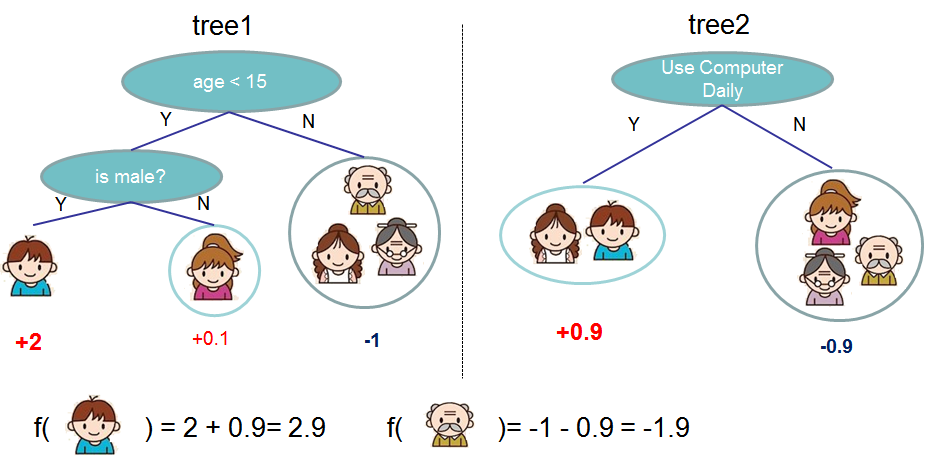
위 그림처럼 최종 예측값은 각 트리의 리프 점수를 모두 합산해서 구했다. 각 트리가 독립적인 구조 q와 리프 가중치 w를 가지며, 새로운 트리를 추가할 때 2차 테일러 근사를 사용해 목적함수를 빠르게 최적화했다.
사실 처음엔 2차 근사 부분이 좀 헷갈렸는데, 알고 보니 핵심은 간단했다. 손실 함수의 1차 미분 g와 2차 미분 h만 있으면, 어떤 손실 함수든 동일한 프레임워크로 최적의 분할을 찾을 수 있다는 것이었다. 이 덕분에 분류, 회귀, 랭킹 등 다양한 태스크에 범용적으로 적용 가능했다.
Split Finding — 진짜 기술은 여기에 있다
트리 학습에서 가장 비용이 큰 부분은 최적의 분할점을 찾는 것이었다. 논문은 세 가지 방향에서 이 문제를 공략했다.
Exact Greedy Algorithm은 모든 가능한 분할점을 열거하는 방법이었다. 정확하지만 데이터가 메모리에 다 올라가야 했다. Approximate Algorithm은 피처의 분위수(quantile)를 기반으로 후보 분할점을 먼저 제안하고, 그 후보들 사이에서만 최적을 찾았다. global 방식은 트리 구축 초기에 한 번만 후보를 정하고, local 방식은 매 분할마다 후보를 재생성했다.
이 부분에서 좀 재밌는 게 있었다. 근사 알고리즘에서 후보 분할점을 정할 때, 각 데이터 포인트의 가중치가 동일하지 않다는 점이었다. 목적함수를 다시 쓰면 h_i가 가중치 역할을 하는 가중 제곱 손실로 변환되는데, 기존의 quantile sketch 알고리즘은 동일 가중치만 지원했다. 그래서 저자들은 weighted quantile sketch라는 새로운 자료구조를 제안했다. merge와 prune 연산에 대해 이론적 보장까지 증명한 부분이 인상적이었다.

각 리프에 속한 데이터의 g, h 통계량을 합산하고 scoring formula를 적용하면 트리 구조의 품질을 평가할 수 있었다. 값이 작을수록 좋은 구조라는 의미였다.
Sparsity-aware Split Finding도 핵심 기여였다. 현실 데이터에는 결측값, 원핫 인코딩으로 인한 0 값 등 희소성이 만연했다. XGBoost는 각 트리 노드에 default direction을 두어, 피처 값이 없는 인스턴스가 자동으로 최적의 방향으로 분류되도록 했다. 비결측 데이터만 순회하면 되니 계산 복잡도가 비결측 엔트리 수에 비례했다.
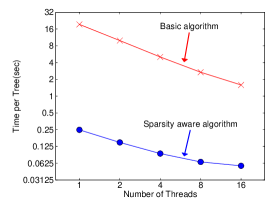
Allstate-10K 데이터셋에서 sparsity-aware 알고리즘이 naive 버전보다 50배 이상 빠른 결과를 보여줬다. 원핫 인코딩이 많은 실무 데이터에서 이 차이는 결정적이었다.
시스템 설계 — 논문의 숨은 주인공
사실 이 논문에서 가장 감탄한 부분은 알고리즘이 아니라 시스템 설계였다.
Column Block 구조는 데이터를 CSC(Compressed Sparse Column) 포맷으로 저장하고, 각 컬럼을 피처 값 기준으로 미리 정렬해뒀다. 이 전처리를 한 번만 하면 이후 반복에서 재사용 가능했다. 정렬된 컬럼 위를 선형 스캔하면서 분할 후보를 평가하니, 원래 O(Kd||x||_0 log n)이던 복잡도가 O(Kd||x||_0 + ||x||_0 log n)으로 줄었다. log n 팩터 하나를 제거한 것이었다.
Cache-aware Access는 솔직히 처음엔 "이게 왜 논문에?" 싶었다. 그런데 읽어보니 이해가 됐다. 블록 구조에서 gradient 통계량은 피처 값 순서로 접근하는데, 이는 비연속적 메모리 접근이었다. CPU 캐시 미스가 발생하면 성능이 크게 떨어졌다. 각 스레드에 내부 버퍼를 할당하고 미니배치 방식으로 누적하는 prefetching 기법을 적용했더니, 대규모 데이터셋에서 2배 빨라졌다.
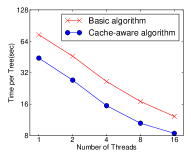
Allstate 10M과 Higgs 10M 데이터셋에서 cache-aware 알고리즘이 기본 알고리즘 대비 약 2배의 성능 향상을 보여줬다. 데이터셋이 클수록 캐시 미스의 영향이 커지는 것을 확인할 수 있었다.
Out-of-core Computation도 실용적이었다. 블록 압축으로 디스크 I/O 비용을 줄이고, 여러 디스크에 데이터를 샤딩해서 읽기 처리량을 높였다. 압축만으로 3배, 샤딩 추가로 2배의 속도 향상을 달성했다.
결과를 보면서 느낀 점
실험 결과에서 눈에 띄는 점이 몇 가지 있었다. 먼저 Higgs-1M 분류 실험에서 XGBoost는 scikit-learn보다 10배 이상 빠르면서 동일한 정확도(AUC 0.8304)를 달성했다. R의 gbm은 빠르긴 했지만 AUC가 0.6224로 처참했는데, 전체 트리 대신 한 가지만 확장하는 greedy 방식 때문이었다.
분산 실험이 더 인상적이었다. 32개 EC2 노드에서 Spark MLLib 대비 반복당 10배 이상 빨랐고, H2O 대비 2.2배 빨랐다. 더 중요한 건 Spark과 H2O가 메모리 부족으로 처리 못하는 17억 건 데이터를 XGBoost는 out-of-core 방식으로 처리했다는 점이었다. 심지어 4대의 머신만으로도 전체 데이터를 처리할 수 있었다.
개별 최적화 기법 하나하나보다, 이것들을 하나의 시스템으로 결합했을 때의 시너지가 논문의 진짜 기여였다.
솔직한 생각
이 논문을 읽고 나서 가장 크게 느낀 건, 좋은 ML 시스템은 알고리즘만으로 완성되지 않는다는 것이었다. 캐시 접근 패턴, 디스크 I/O 최적화, 데이터 압축 같은 시스템 레벨의 고민이 알고리즘 혁신만큼이나 중요했다.
아쉬운 점도 있었다. 논문이 2016년 기준이다 보니 GPU 활용에 대한 논의가 없었다. 이후 XGBoost에 GPU 지원이 추가된 걸 알고 있는데, 그 부분의 시스템 설계도 궁금하다. 또한 하이퍼파라미터 튜닝에 대한 가이드가 부족한 편이었다. max depth 8, shrinkage 0.1이라는 설정을 사용했는데, 이 선택의 근거가 좀 더 자세했으면 좋았을 것이다.
다음에는 LightGBM 논문을 읽어볼 생각이다. XGBoost 이후에 나온 시스템이 어떤 병목을 추가로 해결했는지 비교해보면 재밌을 것 같다. CatBoost도 범주형 피처 처리 관점에서 흥미로운 접근을 했다고 들었다. 결국 트리 부스팅 생태계 전체를 이해하려면 이 세 논문을 나란히 놓고 봐야 한다고 생각한다.
'PaperReview' 카테고리의 다른 글
| Segment Anything (0) | 2026.05.05 |
|---|---|
| The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models (0) | 2026.02.13 |
| [Column] AI Stigma: Why Some Users Resist AI’s Help (1) | 2026.02.08 |
| [FLAM]Finetuned Language Models Are Zero-Shot Learners (0) | 2026.02.08 |
| Visual Instruction Tuning (0) | 2026.02.08 |