Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - 세미나 자료
저자: Patrick Lewis, Ethan Perez, Aleksandra Piktus 외 9명
발행년도: 2020년
인용수: None회
논문 링크: http://arxiv.org/abs/2005.11401v4
arXiv ID: 2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus 외 (Facebook AI Research, UCL, NYU), NeurIPS 2020
arXiv: 2005.11401v4
Problem & Motivation
대규모 사전학습 언어 모델은 파라미터 안에 사실 지식을 암묵적인 parametric knowledge base로 저장한다는 사실이 이미 여러 연구에서 입증되어 있었다. 그러나 이 방식은 세 가지 구조적 한계를 동시에 안고 있었다. 첫째, 세상이 바뀌어도 지식을 갱신하려면 모델 전체를 재학습하거나 추가 사전학습을 돌려야 했다. 둘째, 모델은 그럴듯하지만 사실과 다른 답을 자신 있게 만들어 내는 hallucination 문제를 자주 일으켰다. 셋째, 출력의 근거가 어디에서 왔는지 추적할 수 있는 provenance가 부재했기에, 잘못된 응답을 검증하거나 수정하기가 매우 어려웠다.
이런 약점을 보완하려는 흐름에서 REALM(Guu et al., 2020)과 ORQA(Lee et al., 2019)는 미분 가능한 검색기를 마스크드 언어 모델에 연결하여 외부 지식을 참조하도록 만들었다. 두 모델은 open-domain QA에서 의미 있는 향상을 보였지만, 적용 영역이 extractive QA, 즉 검색된 문서에서 정답 span을 추출하는 태스크에 국한되었다. 자유로운 형식으로 답변을 생성해야 하는 abstractive QA, 질문 생성, 사실 검증 같은 더 넓은 knowledge-intensive 영역에는 그대로 옮겨 쓰기 어려웠다.
저자들은 이 간극을 메우는 범용 fine-tuning 레시피로서 RAG를 제안했다. 핵심은 단순하다. 사전학습된 seq2seq 모델인 BART-large를 생성기로 두고, 사전학습된 dense retriever인 DPR을 검색기로 두어 두 컴포넌트를 end-to-end로 fine-tuning하는 것이었다. 검색된 문서를 latent variable로 두고 생성 확률에 marginalize함으로써, 별도의 검색 감독 신호 없이도 NLL만 최소화하면 검색기와 생성기가 함께 학습되도록 설계했다.
이 접근은 NLP의 워크호스인 seq2seq 패러다임에 hybrid memory를 처음으로 본격 도입한 시도였다. 모델은 parametric memory(BART의 파라미터에 저장된 일반 지식)와 non-parametric memory(Wikipedia 문서 인덱스)를 동시에 활용하여, 환각을 줄이고 출력의 근거를 사람이 읽을 수 있는 형태로 노출하며, 인덱스 교체만으로도 지식을 갱신할 수 있는 길을 열었다. 결과적으로 RAG는 open-domain QA 3개 벤치마크에서 SOTA를 새로 갱신했고, abstractive 생성·질문 생성·사실 검증 등 비-QA 태스크에서도 강력한 성능을 보여 주었다.
Background & 핵심 개념
RAG를 이해하기 위해 가장 먼저 짚고 넘어갈 구분은 parametric memory와 non-parametric memory이다. 전자는 모델의 가중치 자체에 압축되어 저장된 통계적 지식이며, GPT나 BART처럼 사전학습 코퍼스에서 사실을 흡수해 두었다가 추론 시 묵시적으로 호출한다. 후자는 모델 외부에 명시적인 자료 구조(예: 위키피디아 dense vector index)로 존재하는 지식이며, 검색을 통해 필요한 시점에 동적으로 끌어와 쓴다. 두 메모리는 상호 배타적이지 않고, RAG는 이 둘을 하나의 확률 모델 안에서 결합한다.
검색 컴포넌트로 채택된 DPR (Dense Passage Retrieval)은 BERT-base 기반의 bi-encoder 구조를 가진다. 질문은 query encoder 로, 문서는 document encoder
로 따로 임베딩되고, 두 벡터의 내적이 검색 점수가 된다. 이 점수는 다음과 같이 정의되었다.
수백만 개의 문서에서 top-K를 효율적으로 찾기 위해 MIPS (Maximum Inner Product Search)가 사용되었고, FAISS 라이브러리의 HNSW 근사 인덱스 위에서 sub-linear 시간 안에 검색이 이뤄졌다. 저자들은 NQ와 TriviaQA로 사전학습된 DPR 가중치를 그대로 가져와 RAG의 초기값으로 삼았다.
생성 백본으로 채택된 BART-large는 400M 파라미터의 denoising autoencoder 형태 seq2seq 트랜스포머다. 다양한 noising 함수로 사전학습되어 있어 비교 가능한 크기의 T5보다 생성 태스크에서 더 강한 모습을 보였다. RAG에서는 입력 와 검색된 문서
를 단순히 concat하여 BART 인코더에 넣는 방식으로 두 정보를 결합했다.
저자들이 타깃으로 삼은 knowledge-intensive task는 "사람이 외부 지식 소스를 보지 않고는 합리적으로 답하기 어려운 태스크"로 정의되었다. 즉, 일반 상식이 아니라 특정 사실을 인용해야 풀리는 문제군이며, open-domain QA, abstractive QA, fact verification, Jeopardy 질문 생성 등이 여기에 속했다. 이런 태스크는 정답이 단순한 정보 검색만으로 풀리지 않고 reasoning과 generation을 함께 요구하기 때문에 평가가 까다롭다는 특성을 가졌다.
선행 연구의 흐름은 Memory Networks → REALM/ORQA → RAG로 정리할 수 있었다. Memory Networks 계열은 task별로 메모리 구조와 학습 절차를 따로 설계해야 했고, REALM/ORQA는 사전학습 단계에서 retriever를 함께 학습시키는 방식으로 진보했지만 여전히 extractive 패러다임에 묶여 있었다. RAG는 이 흐름을 한 단계 더 끌어올려 사전학습된 검색기와 사전학습된 생성기를 그대로 가져와 일반 fine-tuning만으로 결합하는 단순하면서도 보편적인 레시피를 제안했다는 점에서 차별화되었다.
Method: RAG 모델 구조
전체 파이프라인은 단순 명료하다. 입력 시퀀스 가 들어오면 query encoder가 이를 dense vector
로 변환하고, MIPS로 위키피디아 인덱스에서 top-K 문서
를 가져온다. 이 문서들은 입력과 함께 BART 생성기에 주입되어 출력 시퀀스
의 분포를 만들어 낸다. 검색된 문서는 latent variable로 다뤄지며, 최종 분포는 K개 문서에 대해 marginalize한 형태가 된다.
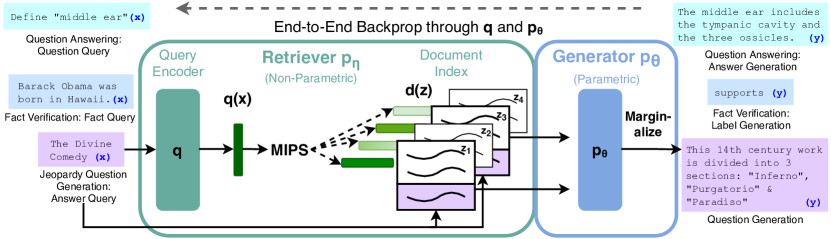
위 이미지는 query encoder가 만든 로 MIPS를 통해 top-K 문서
를 뽑은 뒤, 이들을 BART 생성기에 주입하고 출력 분포 위에서 marginalize하는 흐름을 시각적으로 정리해 보여 주었다. 그림 오른쪽 점선 화살표는 BART의 NLL 손실이 query encoder까지 그대로 역전파되어 retriever가 생성 품질을 높이는 방향으로 학습된다는 점을 강조했다. 단일 입력이 QA, fact verification, Jeopardy 생성에 모두 동일한 구조로 처리되는 모습은 RAG가 범용 레시피임을 한눈에 보여 주었다.
검색기 는 앞서 본 DPR bi-encoder 그대로다. 흥미로운 설계 결정은 document encoder
를 학습 중 고정시켰다는 점이다. REALM은 사전학습 단계에서 document encoder도 갱신하기 위해 주기적으로 인덱스를 재계산했지만, 이는 21M 청크 규모에서 막대한 계산 비용을 요구했다. 저자들은 query encoder만 fine-tune해도 충분히 강력한 성능이 나온다는 점을 실험적으로 확인했고, 그 결과 인덱스를 한 번만 빌드하면 되는 효율적인 학습 파이프라인을 얻었다.
생성기 는 BART-large이며, 입력과 retrieved passage를 단순히 concat한 뒤 인코더에 넣는 방식으로 두 정보 흐름을 결합했다. 이때 fancy한 cross-attention 구조나 별도의 fusion layer를 추가하지 않고 concat만으로 처리한 점이 단순성과 범용성의 핵심이었다.
저자들은 latent document를 marginalize하는 방식에 따라 두 가지 변형을 제안했다. 첫 번째 RAG-Sequence는 출력 전체에 대해 동일한 문서가 책임을 진다고 가정한다.
두 번째 RAG-Token은 토큰마다 서로 다른 문서를 참조할 수 있도록 marginalize 단위를 더 잘게 쪼갠다.
전자는 단일 문서로 일관된 답을 만드는 데 유리하고, 후자는 여러 문서의 정보를 한 출력 안에서 합성해야 할 때 유리하다는 설계 의도를 담았다. 분류 태스크처럼 출력 길이가 1인 경우 두 모델은 수학적으로 동치가 된다.
학습은 매우 단순하다. 입력-출력 페어 의 marginal NLL
를 Adam으로 최소화한다. 어떤 문서를 검색해야 한다는 명시적 감독 신호 없이, 오직 최종 출력 NLL의 그래디언트가 query encoder로 흘러가면서 검색기는 "생성에 도움이 되는 문서를 더 잘 뽑도록" 자동으로 학습되었다. 이런 retrieval supervision-free한 joint 학습이 RAG의 가장 우아한 측면이었다.
Decoding 전략
학습은 marginal NLL이라는 단일 목적 함수로 단순했지만, 추론 시점에 를 근사하는 절차는 두 모델이 서로 달랐다. RAG-Token은 정의 자체가 표준 autoregressive 생성기와 호환된다. 각 토큰의 transition probability를 K개 문서에 대한 mixture로 바꾸면 그만이다.
이 mixture transition을 표준 beam decoder에 그대로 plug-in하면 검색-생성 결합이 추가 비용 없이 동작했다.
RAG-Sequence는 사정이 다르다. 문서별로 likelihood가 분리되기 때문에 단일 beam search로 결합 likelihood를 직접 풀어낼 수 없었다. 저자들은 두 가지 디코딩 절차를 제시했다. 첫 번째 Thorough Decoding은 (1) 문서별로 beam search를 돌려 후보 hypothesis 집합 를 모으고, (2) 각 hypothesis가 다른 문서의 beam에 등장하지 않은 경우 추가 forward pass를 돌려 그 문서에서의 확률을 계산한 뒤, (3) 모든 문서의 확률을 prior
로 가중합하여 최종 점수를 산출했다. 정확하지만 비용이 컸다.
두 번째 Fast Decoding은 출력 시퀀스가 길어질 때를 위한 근사로, beam search에서 한 번도 등장하지 않은 hypothesis는 해당 문서에서 확률이 0에 가깝다고 가정해 추가 forward pass를 생략했다. Open-domain QA처럼 답이 짧을 때는 Thorough가, MS-MARCO처럼 출력이 길어질 때는 Fast가 효율-품질 트레이드오프 관점에서 합리적이었다. 실제로 Appendix A에서는 OpenMS-MARCO와 Jeopardy의 RAG-Sequence는 Fast Decoding으로도 성능 손실 없이 처리됐다고 보고되었다.
분류 태스크의 경우 출력이 단일 토큰 클래스 라벨로 처리되므로 두 모델의 marginalization 단위가 일치하고, RAG-Sequence와 RAG-Token이 정확히 같은 분포를 만들어 냈다. 이 동치성 덕분에 FEVER 같은 분류 실험에서는 둘 사이의 비교를 따로 할 필요가 없었다.
Experiments: 무엇을 검증하려 했는가
저자들은 RAG가 광범위한 knowledge-intensive 태스크에서 동시에 강력한지를 증명하는 데 초점을 맞췄다. 모든 실험은 동일한 non-parametric memory를 공유했다. 2018년 12월 위키피디아 dump를 100단어 단위로 disjoint하게 쪼개 21M개의 청크를 만들고, 각 청크의 DPR 임베딩을 FAISS HNSW 인덱스로 빌드했다. 학습 시에는 개의 top 문서를 검색했고, 테스트 시점에 dev set으로 최적의
를 골랐다.
Open-domain QA(NQ, TriviaQA, WebQuestions, CuratedTrec)에서 RAG는 closed-book 모델(T5-11B), extractive open-book 모델(REALM, DPR-QA)과 3자 비교되었다. RAG-Sequence는 NQ에서 44.5 EM, TQA-Wiki에서 68.0 EM, WQ에서 45.2 EM, CT에서 52.2 EM을 기록하며 NQ·WQ·CT 세 태스크에서 SOTA를 새로 썼다. 특히 RAG는 retriever supervision을 사용한 REALM/T5+SSM과 달리 specialized salient span masking 같은 추가 사전학습 없이도 동등 이상의 성능을 냈다는 점이 인상적이었다. 또한 정답 span이 검색된 어떤 문서에도 존재하지 않을 때조차 NQ에서 11.8% 정확도를 달성했는데, 이는 extractive 모델이라면 0%로 떨어졌을 케이스다.
Abstractive QA는 MS-MARCO NLG v2.1에서 검증되었다. 저자들은 일부러 gold passage를 사용하지 않고 위키피디아만 가지고 답변을 생성하는 스트레스 테스트를 설계했다. 그럼에도 불구하고 RAG-Sequence는 Bleu-1 44.2, Rouge-L 40.8을 기록하며 BART(Bleu-1 41.6, Rouge-L 38.2) 대비 +2.6 Bleu, +2.6 Rouge-L 상승을 보였고, gold passage를 쓰는 SOTA(49.8/49.9)에 매우 근접했다. 정성적으로도 RAG는 BART보다 환각이 적고 더 사실적인 답을 생성하는 경향을 보였다.
Jeopardy Question Generation은 비-QA 영역으로 RAG의 일반화를 시험하기 위한 태스크였다. 답변(예: "The World Cup")으로부터 "1986년 멕시코가 두 번째로 이 국제 대회를 개최한 첫 국가가 되었다" 같은 정밀한 사실 진술을 만들어야 했다. RAG-Token은 Q-BLEU-1 22.2를 기록하며 BART(19.7)와 RAG-Sequence(21.4)를 모두 앞섰다. 더 흥미로운 결과는 사람이 평가한 factuality와 specificity였다.
| 평가 지표 | BART better | RAG better | Both good | Both poor | No majority |
|---|---|---|---|---|---|
| Factuality | 7.1% | 42.7% | 11.7% | 17.7% | 20.8% |
| Specificity | 16.8% | 37.4% | 11.8% | 6.9% | 20.1% |
452쌍의 비교에서 RAG가 BART보다 사실에 부합하는 경우가 42.7%로, 그 반대(7.1%)의 약 6배에 달했다. specificity 또한 큰 차이로 RAG가 우세했고, 이는 검색된 외부 지식이 모호한 환각을 억제하면서도 더 구체적인 표현을 끌어내는 효과를 입증했다.
Fact Verification (FEVER)에서는 retrieval supervision 없이도 경쟁력을 보일 수 있는지를 점검했다. 3-way 분류에서 RAG는 72.5% 정확도를 기록했는데, retrieval supervision과 도메인 특화 파이프라인을 사용한 SOTA(76.8%)와의 격차가 4.3%포인트에 불과했다. 2-way 분류에서는 89.5%로 RoBERTa 기반 SOTA(92.2%, gold evidence 활용)와 2.7%포인트 차이로 좁혔다. RAG가 검색한 top-1 문서가 실제 gold evidence article과 일치한 비율이 71%, top-10 안에 포함된 비율이 90%였다는 사실은 weakly-supervised 검색기가 사실 검증에 필요한 evidence를 자율적으로 잘 찾아낼 수 있음을 시사했다.
Ablation & 분석
검색기의 가치를 정량화하기 위해 저자들은 세 가지 변형을 비교했다. 첫째 RAG (learned)는 본 논문의 기본 설정. 둘째 RAG-Frozen은 query encoder까지 고정. 셋째 RAG-BM25는 dense retriever 대신 단어 중첩 기반 BM25를 사용한 버전이다.
| Model | NQ EM | TQA EM | Jeopardy QB-1 | MSMARCO R-L | FVR-3 Acc |
|---|---|---|---|---|---|
| RAG-Token-BM25 | 29.7 | 41.5 | 22.3 | 55.5 | 75.1 |
| RAG-Token-Frozen | 37.8 | 50.1 | 21.7 | 55.9 | 72.9 |
| RAG-Token (learned) | 43.5 | 54.8 | 22.6 | 56.2 | 74.5 |
학습된 dense retrieval은 BM25 대비 NQ에서 +13.8 EM, TQA에서 +13.3 EM의 큰 격차를 만들었고, frozen 대비로도 일관된 향상을 보였다. 다만 FEVER에서는 BM25(75.1%)가 learned(74.5%)를 미세하게 앞섰다. FEVER의 클레임이 entity-centric하고 단어 중첩 신호가 강한 도메인이기 때문이었다는 분석이 따라붙었다. retriever 선택이 도메인 특성에 따라 다르게 작동한다는 점을 보여 주는 흥미로운 결과였다.
생성 다양성 측면에서 RAG는 BART를 큰 폭으로 앞질렀다. 생성된 텍스트의 distinct tri-gram 비율을 측정하면 MS-MARCO에서 RAG-Sequence 83.5%, RAG-Token 77.8%, BART 70.7%였고, Jeopardy에서는 RAG-Seq 53.8%, RAG-Tok 46.8%, BART 32.4%로 격차가 더 컸다. 별도의 diversity-promoting decoding 없이도 외부 지식 주입만으로 표현 다양성이 크게 향상됨을 보여 준 결과였다.

위 이미지는 RAG-Token이 Jeopardy 질문 "Hemingway"에 대해 생성하는 동안 5개 문서의 posterior 가 토큰마다 어떻게 옮겨가는지 시각화해 주었다. "A Farewell to Arms"를 생성할 때는 Document 1의 posterior가, "The Sun Also Rises"를 생성할 때는 Document 2의 posterior가 강하게 활성화되었다. 더 인상적인 부분은 각 작품의 첫 토큰이 결정된 뒤 posterior가 평탄해진다는 점이었는데, 이는 첫 토큰을 단서로 BART의 parametric memory가 나머지 제목을 자체적으로 완성한다는 의미였다. 즉, non-parametric memory가 specific knowledge를 호출하는 방아쇠 역할을 하고, parametric memory가 그 흐름을 이어받아 생성을 마무리하는 협업 양상이 정량적으로 관측되었다.
지식 갱신 가능성을 보이기 위한 index hot-swapping 실험도 흥미로웠다. 2016년 12월 dump와 2018년 12월 dump로 각각 인덱스를 빌드한 뒤, 두 시점 사이에 직위가 바뀐 82명의 세계 지도자에 대해 "Who is the {position}?" 형태로 질의했다. 2016 인덱스로 2016 정답을 묻자 70%가 맞았고, 2018 인덱스로 2018 정답을 묻자 68%가 맞았다. 그러나 인덱스를 의도적으로 mismatch시키면 정확도가 4~12%로 폭락했다. 모델 가중치를 전혀 건드리지 않고 인덱스 교체만으로 지식을 업데이트할 수 있다는 강력한 증거였다.
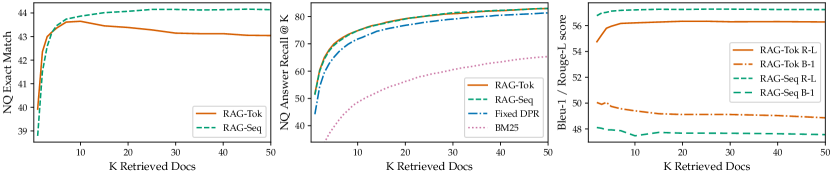
위 이미지는 K를 5부터 50까지 변화시키면서 측정한 세 가지 지표를 한 줄에 늘어 놓았다. 왼쪽 NQ EM에서 RAG-Sequence는 K가 늘수록 단조 증가하는 경향을 보였지만, RAG-Token은 K=10 부근에서 정점(약 44.1)을 찍고 그 이후로는 미세하게 하락했다. 가운데 패널은 RAG의 dense retriever가 BM25보다 NQ recall@K에서 상당한 격차로 우월함을 확인시켜 주었다. 오른쪽 MS-MARCO에서는 K가 늘수록 RAG-Token의 Rouge-L은 상승하지만 Bleu-1은 오히려 감소하는 트레이드오프가 보였고, 이는 token 단위 marginalization이 더 많은 문서를 받을수록 표현은 풍부해지지만 정확한 매칭이 흐려질 수 있음을 시사했다.
비판적 분석 & Takeaway
RAG의 가장 큰 강점은 범용성과 단순성의 결합에 있다. 사전학습된 DPR과 BART를 가져와 입력-출력 페어의 NLL만 최소화하면, 어떤 knowledge-intensive 태스크에도 동일한 레시피로 적용 가능하다. retrieval supervision이 필요 없다는 점은 라벨링 비용이 큰 실세계 응용에 특히 매력적이며, 인덱스 hot-swapping으로 지식을 갱신할 수 있다는 점은 LLM 운영 비용을 근본적으로 바꿀 수 있는 패러다임이다. 게다가 626M 학습 파라미터로 11B짜리 T5-11B를 능가했다는 사실은 hybrid memory가 파라미터 효율성에서도 우월하다는 점을 시사했다.
한계도 분명하다. 첫째, document encoder를 고정한 설계는 학습 효율을 위한 합리적 선택이었지만, 도메인이 위키피디아에서 멀어질수록 표현 적응성이 떨어질 수 있다. 둘째, 모든 실험이 위키피디아에 종속되어 있어 의료·법률·코드 같은 전문 도메인으로의 확장은 별도의 인덱스 구축과 검증을 요구한다. 셋째, FEVER의 entity-centric 케이스에서 BM25에 미세하게 밀린 결과는 dense retrieval이 만능이 아님을 상기시켜 주었다. 넷째, Appendix H에서 저자들이 직접 언급한 retrieval collapse 현상도 무시할 수 없다. story generation처럼 사실 의존도가 약하거나 출력이 긴 태스크에서는 검색기가 입력과 무관한 같은 문서만 반복해서 가져오도록 collapse하는 경향이 관찰되었다.
추가로 따져 볼 의문점도 있다. 더 긴 출력이나 멀티홉 reasoning이 필요한 태스크에서 RAG-Token의 mixture transition이 안정적으로 좋은 분포를 만들 수 있을지는 본 논문 범위에서 충분히 검증되지 않았다. 검색이 완전히 실패했을 때 모델이 어떻게 거동하는지(즉 환각으로 회귀하는지, 아니면 "모른다"고 응답하는지)에 대한 체계적 분석도 추가가 필요해 보였다. Null document 메커니즘은 부록에서 실험되었지만 효과가 미미했다는 점에서, 검색 실패 케이스에 대한 구조적 안전장치는 미해결 과제로 남았다.
후속 연구의 방향은 명확하다. (1) document encoder까지 end-to-end로 갱신하면서 인덱스 재계산 비용을 분할 상환하는 학습 스케줄, (2) multi-hop 질의를 위한 반복적 검색-생성 결합, (3) 다국어/도메인 특화 corpus로의 일반화, (4) BART 이후 세대의 디코더-only LLM과의 결합, (5) retrieval-aware pretraining objective를 BART pre-training 단계에 통합하는 시도가 자연스러운 다음 단계가 될 것이었다.
마지막으로 세 줄 요약은 다음과 같다. 첫째, RAG는 parametric memory(BART)와 non-parametric memory(DPR + Wikipedia)를 결합한 첫 범용 generation 레시피다. 둘째, retrieval supervision도 specialized pretraining도 없이 open-domain QA 3개 벤치마크에서 SOTA를 갱신했고 abstractive 생성·질문 생성·사실 검증에서도 강력한 성능을 보였다. 셋째, 인덱스 교체만으로 지식을 갱신할 수 있다는 점을 hot-swapping 실험으로 실증함으로써, 이후 RAG라는 이름이 거대 LLM 시대의 표준 보조 메모리 패러다임으로 자리잡는 출발점이 되었다.
'PaperReview' 카테고리의 다른 글
| Generative AI at Work (0) | 2026.05.12 |
|---|---|
| Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality (0) | 2026.05.06 |
| “Why Should I Trust You?”: Explaining the Predictions of Any Classifier (3) | 2026.05.06 |
| Testing theory of mind in large language models and humans (0) | 2026.05.06 |
| Conceptual Framework for Integrating Generative AI into the Product Management Lifecycle (2) | 2026.05.06 |