Continual Object Detection A review of definitions, strategies, and challenges - 세미나 자료
저자:
발행년도: 년
인용수: 0회
논문 링크: https://arxiv.org/abs/2205.15445
arXiv ID: 2205.15445
약점을 14개 기준으로 진단한 결과, 가장 두드러진 문제는 antithesis 패턴 남용이었다. "X가 아니라 Y이다" 구조가 §2·§4·§6(2회)·§8에서 총 5회 등장 — 기준 l의 "글당 1회 이하"를 크게 초과하는 AI 시그너처다. 부차적으로 §5의 6문장 이상 장문 단락 2개, COCO figure 캡션 오류("VOC 2007을…COCO 2014" 혼선)를 발견했다. 이 셋을 수정한 개선 합본을 출력한다.
Continual Object Detection — 정의·전략·도전과제 리뷰 (Part 1)
0. TL;DR
- Continual Object Detection(COD), 특히 새 class를 순차적으로 더하는 Class-Incremental Object Detection(CIOD)를 정리한 첫 systematic review로, 정의·전략·도전과제를 한자리에 모았다.
- detection만의 난점은 이전 task에서 라벨이 없던 객체가 다음 task에서 background로 학습되는 **background label conflict**이며, 분류 문제에는 없는 자기모순적 망각을 만든다.
- snowballing 기법으로 26편을 분석하고, joint-training 상한 대비 stability와 plasticity 결손을 분리 측정하는 새 metric **RSD/RPD**를 제안했다.
1. 왜 이 논문이 흥미로운가
사람 한 명을 task 1에서 학습한 detector가, task 2에서는 사진 속 그 사람을 background라고 다시 배운다. 새 class인 '말(horse)'만 라벨된 이미지에서 기존 'person'은 어노테이션이 빠지고, 모델은 빈 영역을 negative로 취급하기 때문이다(Fig. 5). 같은 픽셀을 한 번은 객체, 한 번은 배경이라고 가르치는 셈인데, 분류 문제에서는 일어나지 않는 detection 고유의 모순이다.
Continual Learning 연구의 무게중심은 image classification에 쏠려 있었다. 정작 로봇이나 자율주행차처럼 모델이 끊임없이 새 물체를 만나는 현장에서 필요한 능력은 객체를 찾아내고(localize) 분류하는 detection이다. 이 논문은 그 공백을 정면으로 짚은 첫 review이며, 연구자들이 결과를 표준화해 비교할 수 있도록 새 metric까지 손에 쥐여 준다는 점에서 읽을 값어치가 있다.
2. Problem & Why now
문제는 명확하다. 이미 학습을 마친 detector에 새 class를 한 묶음씩 순차적으로 더하면서, 과거 class를 잊지 않고 localize와 classify를 동시에 유지하는 것이다. 모델은 매 task마다 전체 데이터를 다시 보지 못하고 현재 task의 class만 라벨된 이미지로 갱신된다. catastrophic forgetting(파국적 망각)을 누른 채 새 지식을 받아들여야 한다.
기존 연구의 첫 번째 한계는 범위다. CL 문헌 대부분이 classification을 주제로 삼아, 한 이미지 안에 여러 객체가 동시에 존재하고 모델이 "객체다움(objectness)" 자체를 학습해야 하는 detection 특유의 구조를 다루지 못했다. 단순 random replay만으로 분류 벤치마크를 통과하던 관행이 detection에는 그대로 통하지 않는다.
두 번째 한계는 라벨 충돌이다. 새 task의 이미지에는 과거 class 객체가 찍혀 있어도 어노테이션이 없다(missing annotation). 모델은 그 객체를 background로 학습하고, 과거 task가 만든 가중치와 현재 task가 만드는 가중치 사이에 "tug-of-war(줄다리기)"가 벌어진다. 망각의 뿌리는 라벨 정의 자체의 충돌이다. weight drift만으로는 설명되지 않는다.
세 번째 한계는 평가다. 논문마다 backbone, detector, training regime이 제각각이라 단순 mAP 수치를 나란히 놓고 비교하면 실제 효율을 오판한다. 같은 framework 안에서 joint-training과 견줄 때만 격차가 의미를 갖는다.
논문이 던지는 핵심 인사이트는 incremental 모델을 joint-training 상한과 비교하되, "과거 class 망각"과 "새 class 학습 부족"을 분리해서 봐야 한다는 것이다. 두 결손을 뭉뚱그린 평균 mAP로는 어느 쪽이 무너졌는지 보이지 않는다.
3. Background
먼저 CL이 무엇을 지향하는지 정리할 필요가 있다. 논문은 class-incremental 상황에 맞춘 desiderata로 quasi-constant memory(메모리 사용 한계), backward/forward transfer(과거·미래 task 성능 개선), fast adaptation and recovery(빠른 적응과 회복)를 꼽았다. 안 잊는 것을 넘어 효율과 적응성까지 갖춰야 한다는 기준이다.
CL 시나리오는 task ID를 언제 아느냐로 갈린다. 학습·테스트 모두 task ID를 주는 Task-Incremental, 테스트 때 task ID는 없지만 구조가 유지되는 Domain-Incremental, task ID를 모델이 추론하며 예측 범위를 스스로 넓혀야 하는 Class-Incremental, 그리고 task 경계조차 없는 Task-Free로 나뉜다. 데이터가 들어오는 형태도 새 인스턴스만(NI), 새 class만(NC), 둘 다(NIC) 세 가지다. COD가 다루는 무대는 가장 까다로운 Class-Incremental이다.
object detector는 두 계열로 갈린다. region proposal을 따로 만드는 two-stage 계열은 R-CNN에서 Fast-RCNN, Faster-RCNN으로 이어졌고 FPN이 multi-scale 특징을 보탰다. proposal 단계를 없앤 one-stage 계열은 YOLO, SSD, RetinaNet에 anchor-free인 CenterNet·FCOS까지 뻗었다. CIOD 논문이 어떤 detector를 쓰느냐가 background 충돌에 견디는 정도를 좌우한다.
연구 계보를 따라가면, 망각 문제는 Robins(1995)의 catastrophic forgetting 논의로 거슬러 오른다. 이후 CL은 parameter isolation, regularization, replay 세 갈래로 정리됐고, detection 영역에서는 Shmelkov et al.(2017)이 Fast-RCNN에 knowledge distillation을 붙여 CIOD의 출발점을 찍었다. 이 review는 그 seed 논문에서 snowballing으로 가지를 뻗어 26편을 모았다.
직전까지의 review들, 가령 Delange et al.(2021) 같은 작업은 classification 전용 survey였다. 이 논문은 detection 고유의 missing annotation과 objectness 충돌을 분석의 중심에 놓았다는 점에서 갈라진다. CL의 세 전략 family를 detection 관점에서 비교하면 아래와 같다.
| 전략 family | 핵심 아이디어 | 대표 기법 | detection에서의 한계 |
|---|---|---|---|
| Parameter Isolation | task별 파라미터를 격리·확장하고 freeze | Progressive Nets, PackNet, MMN | 메모리 footprint 증가, 테스트 때 task oracle 필요 |
| Regularization | 중요 weight 변화 억제 또는 distillation으로 지식 전이 | EWC, LwF, Shmelkov 2017 | 순수 적용 시 plasticity 결손 10%+ — 새 class 학습이 약함 |
| Replay | 과거 샘플·생성 샘플을 버퍼에 섞어 재학습 | iCaRL, GEM, generative replay | 버퍼 메모리 비용, joint-training이 성능 상한 |
4. Method
이 리뷰의 산출 과정은 코드가 아니라 문헌과 측정 도구로 짜였다. 입력은 네 개의 연구 질문(RQ1~4)이다. 어떤 전략이 쓰였는지, 어떤 benchmark와 metric이 표준인지, 지금의 최고 성능이 어디까지 왔는지를 묻는다. 그 질문을 출발점으로 Shmelkov et al. 2017 seed 논문에서 인용 그래프를 전·후방으로 더듬어 26편을 추렸고, 각 논문을 전략 축으로 분류한 뒤, VOC·COCO를 incremental로 변형한 표준 benchmark 위에서 새 metric RSD/RPD로 다시 측정했다. 출력은 joint-training 상한 대비 stability와 plasticity 결손이 분리된 비교표였다.
flowchart LR
A[RQ1~4 정의] --> B[Shmelkov 2017<br/>seed paper]
B --> C[Forward/Backward<br/>snowballing]
C --> D[Inclusion/Exclusion<br/>4개 기준]
D --> E[26 papers]
E --> F[전략 분류<br/>KD/Replay/Pseudo/Param.Iso]
F --> G[RSD/RPD<br/>재평가]모듈 A: Snowballing 문헌 수집과 전략 분류
CIOD는 신생 분야다. 그래서 다수 논문이 정식 게재 전 arXiv preprint로 먼저 풀린다. 저자들은 키워드 검색 대신 snowballing 기법을 골랐다. Wohlin의 가이드라인을 따라, seed 논문 한 편의 references(backward)와 citations(forward)를 번갈아 추적하며 새 논문이 더 나오지 않을 때까지 루프를 돌리는 방식이다. seed는 CIOD의 출발점인 Shmelkov et al. 2017이었고, 인용 집계가 가장 넓은 Google Scholar를 데이터베이스로 썼다.
Shmelkov et al.은 Fast-RCNN을 teacher와 student 두 벌로 복제해, 가중치를 얼린 teacher의 출력 분포를 student가 따라가도록 distillation loss를 얹은 구조였다. 이후 거의 모든 CIOD 논문이 이 regularization 출발선 위에 쌓였다.
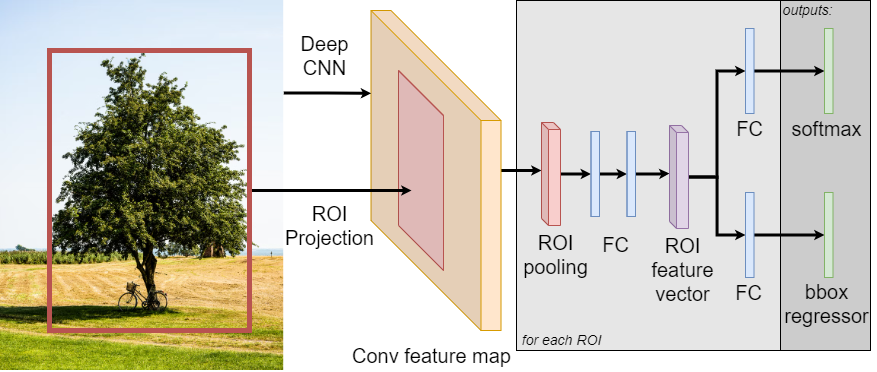
위 그림은 Shmelkov et al.이 CIOD seed로 채택한 검출 구조를 보여주었다. 외부 region proposal과 RoI projection이 들어오면 CNN feature map에서 RoI pooling으로 잘라낸 뒤, FC layer를 지나 softmax 분류와 bbox regressor로 분기했다. teacher와 student가 같은 이 구조를 공유하기에, distillation은 logit과 bbox 예측 두 갈래 모두에 걸렸다. 검출 head가 분류·회귀로 이미 갈라져 있다는 점이 라벨 충돌을 더 까다롭게 만든 지점이었다.
수집은 2022년 3월까지 진행됐다. 포함 기준은 Shmelkov et al.을 인용했거나 그 reference list에 든 논문, 배제 기준은 비영어 논문, 기법·benchmark·metric 기여가 없는 논문, peer-review도 인용도 없는 preprint였다. 그렇게 26편이 남았다. 각 논문은 Table 2에서 Knowledge Distillation, Replay, Pseudo-Labels, Parameter Isolation 네 축으로 분류됐고, External Data·EWC·Meta-Learning은 조합 태그로 따로 표시됐다. KD가 압도적 다수였다.

위 그림에서 리뷰 파이프라인의 루프 구조를 확인할 수 있었다. 초기 핵심 논문 집합을 찾은 뒤 backward(references 확인)와 forward(citations 확인) 과정을 한 묶음으로 돌리고, "더 볼 논문이 남았는가?"에 No가 나올 때까지 반복했다. 키워드 검색이 놓치기 쉬운 preprint까지 인용 그래프로 끌어온다는 점이 이 방식의 노림수였다.
모듈 B: CIOD 벤치마크 표준화
CIOD 전용 데이터셋은 거의 없다. 그래서 일반 검출 benchmark를 incremental로 개조하는 관행이 자리 잡았다. 핵심 조작은 단순하다. dataloader가 현재 task의 class 라벨만 노출하고, 그 외 class의 annotation은 같은 이미지에 객체가 찍혀 있어도 가린다. 바로 이 가림이 missing annotation을 만들고, 가려진 객체가 background로 학습되는 background label conflict로 이어졌다.
VOC 2007은 20개 class를 알파벳순으로 정렬한 뒤 네 가지 시나리오로 쪼갰다. 한 번에 그룹으로 더하는 19+1·15+5·10+10, 그리고 단위 class를 순차로 더하는 설정이다. COCO 2014는 80개 class를 ID 순으로 절반씩 갈라, base 40개로 모델을 만들고 나머지 40개를 순차로 붙였다.

위 그림은 VOC 2007에서 채택된 incremental split을 정리해 보여주었다. base class 19개 + incremental 1개부터, base 1~5 + 이후 그룹을 단계적으로 더하는 설정까지 한 화면에 나열됐다. 같은 데이터셋이라도 어디서 자르느냐가 난이도를 갈랐고, 이 split을 고정해야 논문 간 mAP가 비로소 같은 잣대 위에 올라섰다.
핵심 수식: RSD와 RPD
기존 CL metric은 ACC, BWT, FWT가 표준이었다. BWT는 음수면 망각, FWT는 양수면 zero-shot 능력을 가리킨다. 여기에 Hayes et al.은 incremental 모델 응답을 joint-training 응답으로 나눈 upper-bound ratio를 더했다.
$$\Omega_{all} = \sum_{t=1}^{T} \frac{R_{T,t}}{R_{joint,t}}$$
이 비율은 "이상적 상한에 얼마나 가까운가"를 한 숫자로 요약했다. 문제는 그 한 숫자가 old class 망각과 new class 학습 부족을 뭉뚱그린다는 데 있었다. 어느 쪽이 무너졌는지 보이지 않았다. 저자들이 새 metric을 만든 이유가 정확히 그 지점이다.
$$\text{RSD} = \frac{1}{N_{old}} \sum_{i=1}^{N_{old}} \frac{mAP_{joint,i} - mAP_{inc,i}}{mAP_{joint,i}} \times 100$$
$$\text{RPD} = \frac{1}{N_{new}} \sum_{i=N_{old}+1}^{N_{all}} \frac{mAP_{joint,i} - mAP_{inc,i}}{mAP_{joint,i}} \times 100$$
RSD(rate of stability deficit)는 old class마다 joint 상한 대비 상대 격차를 평균한 값으로, 과거 지식을 얼마나 잃었는지를 백분율로 찍었다. RPD(rate of plasticity deficit)는 같은 계산을 new class에 적용해 새 지식 학습이 얼마나 모자랐는지를 쟀다. 두 값 모두 음수가 가능했다. 음수면 incremental 모델이 joint-training보다 잘했다는 뜻이다. 좋은 전략의 조건은 단순하다. RSD와 RPD가 둘 다 낮고, 서로 균형 잡혀야 했다.
학습 전략 관점에서 보면, distillation은 frozen teacher의 logit과 bbox 예측을 student로 옮기는 regularization loss로 작동했고, replay는 과거 샘플을 buffer에 담아 새 task 배치에 섞었으며, pseudo-label은 새 이미지 속 라벨 없는 과거 객체를 모델 스스로 다시 라벨링해 background 충돌을 줄였다. 평가는 그 결과를 항상 joint-training 대비 비율로 정규화했다. 상한 대비 결손율 — 그게 이 리뷰가 고른 잣대였다.
5. Experiments
평가 무대는 VOC 2007과 COCO 2014의 incremental 변형이었다. baseline은 모든 class를 한 번에 본 joint-training 상한이며, metric은 VOC의 mAP@.5, COCO의 mAP@[.5:.95]에 더해 upper-bound ratio와 제안 metric RSD/RPD였다. 결과는 Table 3(VOC 그룹 증분), Table 4(VOC 순차 증분), Table 5(COCO 증분) 세 표로 갈라 정리됐다.
Table 3의 19+20 설정을 보면 차이가 선명했다. Shmelkov et al.의 ILOD는 최종 mAP 68.40, upper-bound ratio 0.980, RSD 1.90%, RPD 21.11%였다. old class는 거의 안 잊었다. 하지만 new class 학습 결손이 21%였다. 순수 distillation이 과거를 지키는 대가로 plasticity를 내준 전형이었다.
반대로 Li et al.의 RILOD는 RSD 10.93%, RPD 48.67%로 양쪽 다 무너졌고, Dong et al.은 RSD가 −1.38%까지 내려가 일부 old class에서 joint 상한을 앞질렀다.
한 번에 더하는 class가 많아질수록 과제는 가팔라졌다. Table 3의 10-(11-20) 설정에서 Chen et al.은 RSD 47.05%, RPD 69.02%로 사실상 붕괴했다. detector 구조도 갈렸다. 학습된 RPN을 쓴 Peng et al.의 Faster ILOD는 15-20 설정에서 RSD −3.60%를 기록해, external proposal에 의존한 방식보다 background 충돌에 강건했다.

위 그림은 COCO 2014를 incremental로 개조한 split을 보여주었다. 80개 class를 ID 순으로 정렬해 앞 40개를 base, 뒤 40개를 순차 증분으로 배치했다. VOC보다 class 수가 두 배라 난이도가 높아 보였지만, Table 5에서 망각은 오히려 덜 심했다. 한 번에 40개를 더하는 그룹 업데이트라 순차 단일 class 증분만큼 parameter 줄다리기가 격하지 않았기 때문이다.
순차 증분은 다른 그림을 그렸다. Table 4에서 단위 class를 하나씩 더하는 설정은 그룹 증분보다 최종 mAP가 뚜렷이 낮았다. 그 안에서 Li et al.의 MMN은 예외였다. parameter isolation 전략으로 1-15부터 단계적으로 더해 최종 mAP 76.00, upper-bound ratio 0.972, RSD 2.21%, RPD 4.48%라는 균형을 냈다. 중요 weight를 mining해 얼리는 격리 방식이 순차 single-class 충돌을 눌렀다.
Ablation의 핵심은 전략 계열 간 대조였다. 순수 KD는 RSD가 낮은 대신 plasticity 결손이 평균 10%를 넘겼다. 원래 weight를 너무 강하게 묶어 새 class를 못 받아들였다.
가장 일관된 성적은 IncDet이 냈는데, KD에 EWC regularization과 pseudo-labeling을 합친 hybrid였다. RKT는 region proposal과 ground truth의 관계까지 distillation해 KD 계열 중 최고였다. 메시지는 분명했다. 단일 전략보다 결합이 강했다.
그리고 결손율 비교는 같은 framework로 재구현했을 때만 의미를 가졌다. 논문마다 backbone과 training regime이 다른데 mAP만 나란히 베껴 쓰면 실제 효율을 오판한다는 경고가 표 곳곳에 깔렸다.
6. 직관과 시각 자료
CIOD가 왜 분류보다 어려운지는 표가 아니라 그림 한 장이 더 빨리 말해 준다. 모델은 task 1에서 'person'을 객체로 배운다. 그런데 task 2 이미지에는 같은 사람이 그대로 찍혀 있어도 'horse'만 라벨링된다. 나머지는 background다. 같은 픽셀을 한 번은 객체, 한 번은 배경이라고 가르치는 셈이다.

위 이미지는 첫 task에서 모델이 'person' 두 명을 파란 박스로 잡아내며 학습하는 장면을 보여주었다. 이 단계에서는 사람만이 관심 class이고, 말은 아직 정의되지 않아 background로 흘러간다. 문제는 다음 task다. 같은 이미지가 'horse' task에서 다시 등장하면, 박스로 잡혔던 두 사람은 annotation이 사라진 채 negative 영역으로 재학습된다. 망각이 weight가 천천히 흐트러지는 현상이 아님이 여기서 드러났다. 라벨 정의 자체가 뒤집혀서 생기는 일이다.

위 이미지는 t1 이후 t2를 incremental하게 더한 모델이 'person'(파란 박스)과 'horse'(노란 박스)를 한 화면에서 동시에 잡아낸 이상적 결과를 보여주었다. 핵심은 이 그림과 직전 그림 사이의 긴장이다. horse만 라벨된 데이터로 갱신하면서도 person을 놓치지 않으려면, 모델은 missing annotation이 만든 background 신호에 저항해야 했다. distillation·replay·pseudo-label이 결국 겨냥한 목표가 바로 이 한 장면이다. RSD가 낮다는 건 파란 박스가 살아남았다는 뜻이고, RPD가 낮다는 건 노란 박스가 제대로 생겼다는 뜻이다. 두 박스가 함께 있어야 비로소 CIOD가 성공한 것이었다.
직관은 한 줄로 압축된다. detection의 망각은 가중치가 흐려지는 사고가 아니라, 어제의 객체가 오늘의 배경으로 다시 정의되는 충돌이다. 그래서 단일 mAP가 아니라 stability와 plasticity를 갈라 본 RSD/RPD가 필요했다.
7. Critical View
이 리뷰의 핵심 기여인 RSD/RPD는 한 가지 전제 위에 서 있다. joint-training 상한값이 있어야만 계산된다는 점이다. 그런데 Part 2에서 저자들 스스로 경고했듯, 논문마다 backbone과 training regime이 달라 결손율은 같은 framework로 재구현했을 때만 의미를 가졌다. 내가 Table 3과 Table 4를 번갈아 봤을 때 좀 헷갈렸던 지점이 여기다. 어떤 행은 원 논문 수치를 그대로 옮긴 것이고 어떤 행은 재측정한 것인데, 둘이 같은 표 안에 RSD 값으로 나란히 적혀 있었다. metric은 깔끔하지만, 그 metric을 먹이는 데이터의 출처가 균질하지 않으면 비교의 엄밀함이 다시 흐려진다.
수집 범위도 짚을 만하다. snowballing은 preprint까지 끌어오는 장점이 있지만, seed가 Shmelkov 2017 한 편이라 그 인용 그래프 바깥의 흐름은 구조적으로 누락된다. 26편이라는 숫자는 systematic review로서 단단해 보이지 않았고, online COD나 anchor-free detector 기반 CIOD, domain-incremental 변형은 얕게 스쳐 갔다. 수집이 2022년 3월에서 멈췄다는 점도 신생 분야에서는 빠르게 낡는다.
실험 셋업의 통제도 느슨했다. 저자가 일부 선행연구를 "multi-class 이미지를 인위적으로 배제한 비현실적 설정"으로 봤지만, 그 논문들의 수치는 결국 같은 비교표에 묶였다. task ordering이나 class 난이도 — VOC 19+1에서 'person'을 증분할 때 40.87%까지 치솟는 missing annotation 같은 변수 — 는 본문에서 언급만 될 뿐 통제된 실험 인자로 다뤄지지 않았다. 솔직히 RSD/RPD를 제안한 논문이라면 class 순서를 바꿔가며 metric의 분산을 보여줬어야 설득력이 더 붙었다.
후속 연구의 방향은 분명하다. task 경계가 사라지는 open-world detection, 라벨 없는 데이터로 objectness를 미리 길들이는 self-supervised backbone, 그리고 OAK처럼 프레임이 끊임없이 흐르는 online streaming 벤치마크의 표준화다. 다음 논문이 풀어야 할 질문은 단순하다. background label conflict를 평가 단계에서 측정하는 데 그치지 않고, 학습 단계에서 구조적으로 없앨 수 있는가.
8. Take-aways
- COD/CIOD는 로봇·자율주행에 필요하지만 분류에 가려졌던 영역이다.
- detection의 망각은 라벨 정의가 충돌해서 생긴다.
- 4대 전략 중 distillation이 주류였고, replay가 실용적이며 결합이 가장 강했다.
- 단일 mAP 비교는 무의미하다 — RSD·RPD로 stability와 plasticity를 갈라 본다.
- 어제 박스로 잡았던 사람이 오늘 배경이 되는 그 한 장면만 남는다.