Python Outlier Detection
다변량 데이터에 적용가능한 이상치 탐지 방법들이 30여개 이상 구현되어 있는 라이브러리
이상치 탐지 학습용으로 좋아보인다.
1. Credit Card Fraud Detection 실습
1.1 Data 소개
이번 예제에서 사용할 데이터는 캐글에서 제공하는 신용카드 거래 데이터입니다.
2일 동안 발생한 284,807건의 거래 중 492건이 사기 거래(0.172%)이고 변수는 PCA로 가공된 28개의 변수와 시간, 금액 그리고 타겟 클래스 변수가 있습니다.
다른 모델을 사용하지 않고 PyOD의 간단한 알고리즘을 사용하여 사기거래를 이상치로 분류해보려고 합니다.
1.2 적용해 볼 이상치 탐지 알고리즘
최대한 간단하고 명료한 방법론을 먼저 시도해보려고 합니다.
1.2.1. LOF, Identifying Density-Based Local Outliers
- 근처에 있는 데이터의 분포에서 얼마나 떨어져 있는지 판단
- 아래 그림의 O1은 일반적인 거리/분포 기반 방법으로도 이상치로 판단하겠지만,
- O2는 이상치로 판단하기 어려울 수 있음 -> 근처에 있는 데이터만 이용해서 이상치 판단

1.2.2. HBOS, Histogram-based Outlier Score
- 각 변수 별 히스토그램을 그려 outlier score를 계산
- 특정 데이터 포인트가 대부분의 변수에서 이상값이라면 실제 이상값일 가능성이 높을 거라는 가설
- 각 변수 별 히스토그램의 높이의 합으로 outlier score 계산
- 변수 간 독립 가정, 변수가 많아도 빠르게 적용 가능
1.2.3. PCA 기반 이상치 탐지
- PCA는 데이터의 분산을 최대로 하는 축을 찾아내어 projection, 선형적 차원 축소
- 축소된 피처셋을 원본 차원 수로 다시 구성? 하면 재구성 오차 발생(reconstructure error) -> 이상치는 재구성 오차가 큼
- 이상치는 가장 드물게 발생하고 정상 데이터와 달라서 projection 할 때 해당 정보를 반영하지 못함
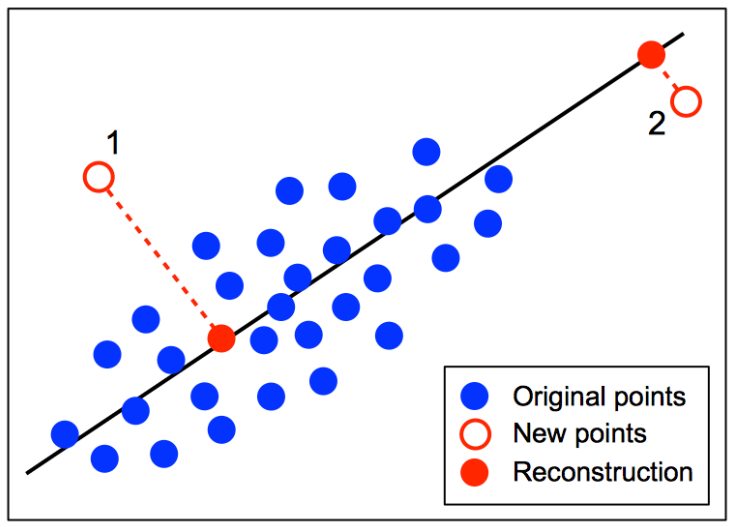
1.2.4. isolation forest
- 정상 군집에서 떨어진 데이터 xo는 적은 수의 공간 분할만으로 isolation 가능
- 의사결정나무를 몇 회 타고 내려가서 고립되는 지를 기준으로 정상치와 이상치 분리

1.3 PyOD 설치 및 알고리즘 적용
PyOD를 설치하고 사용할 이상치 탐지 모델을 불러옵니다.
# import models
!pip install pyod
from pyod.models.lof import LOF
from pyod.models.hbos import HBOS
from pyod.models.pca import PCA
from pyod.models.iforest import IForest
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score사용할 데이터를 캐글에서 다운로드하여 불러와서 봤더니 Amount 변수만 범위가 너무 넓어 간단하게 MinMax 변환하여 진행합니다.
너무 많으면 오래 걸리니 10,000개만 랜덤 추출하여 적용해보겠습니다.
# load data
data0 = pd.read_csv('creditcard.csv')
data0.head(2)
data1 = data0.sample(n=10000, random_state=1025)
X_train = data1.drop(columns=['Time','Class'])
y_train = data1[['Class']]
# standardize
scaler = MinMaxScaler(feature_range=(0,1))
X_train[['Amount']] = scaler.fit_transform(X_train[['Amount']])한 번에 테스트하기 좋게 딕셔너리로 정리하고 이상치 탐지를 해봅니다.
PyOD의 모델들은 outlier_fraction이라는 parameter가 있는데 default값은 0.1이라서 실제 이상치 비율인 0.1727%으로 설정합니다.
실제 분석을 할 때는 알려진 이상치의 비율이 없다면 outlier_fraction 설정하는 데에도 여러 추가 분석이 필요할 것 같네요.
# setting parameters
random_state = np.random.RandomState(1025)
outliers_fraction = 0.0014
# Define seven outlier detection tools to be compared
classifiers = {
'LOF': LOF(contamination=outliers_fraction),
'HBOS': HBOS(contamination=outliers_fraction),
'PCA': PCA(contamination=outliers_fraction),
'Isolation Forest': IForest(contamination=outliers_fraction,random_state=random_state),
}
# model fitting
for i, (clf_name, clf) in enumerate(classifiers.items()):
clf.fit(X_train)
y_pred = clf.labels_
print(clf_name)
print('accuracy : ',round(accuracy_score(y_train,y_pred),3))
print('precision : ',round(precision_score(y_train,y_pred),3))
print('recall : ',round(recall_score(y_train,y_pred),3))
print('f1 : ',round(f1_score(y_train,y_pred),3))
print('-------------------')LOF accuracy : 0.998 precision : 0.429 recall : 0.429 f1 : 0.429
-------------------
HBOS accuracy : 0.998 precision : 0.143 recall : 0.143 f1 : 0.143
-------------------
PCA accuracy : 0.998 precision : 0.286 recall : 0.286 f1 : 0.286
-------------------
Isolation Forest accuracy : 0.998 precision : 0.286 recall : 0.286 f1 : 0.286
-------------------
'Python' 카테고리의 다른 글
| 파이썬 기초 - 02_리스트변경 (0) | 2024.08.19 |
|---|---|
| InterpretML - 설명가능한 머신러닝 (0) | 2024.08.17 |
| Imbalanced-learn : 머신러닝 데이터 불균형 문제 해소 (0) | 2024.08.17 |
| PyGWalker - 파이썬에서 태블로처럼 빠른 EDA 시각화 (0) | 2024.08.17 |
| 파이썬 기초 - 01_과목평균 (0) | 2024.08.17 |