ByteTrack: Multi-Object Tracking by Associating Every Detection Box - 세미나 자료
저자: Yifu Zhang, Peize Sun, Yi Jiang 외 6명
발행년도: 2021년
인용수: None회
논문 링크: http://arxiv.org/abs/2110.06864v3
arXiv ID: 2110.06864
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Yifu Zhang, Peize Sun, Yi Jiang et al. (2021) — arXiv:2110.06864v3 발표자 노트 / 세미나 자료
Problem & Motivation
Multi-Object Tracking(MOT)은 비디오 속 객체의 bounding box와 identity를 동시에 추정하는 작업이다. 현재 가장 널리 쓰이는 패러다임은 tracking-by-detection으로, 매 프레임 detector를 돌리고 검출된 box를 이전 tracklet과 연결하는 방식이다.
문제는 거의 모든 SOTA tracker가 detection score에 단일 threshold 를 걸어 그보다 낮은 box는 통째로 버린다는 점이다. 이 관행은 단순하지만 occlusion이 발생할 때 객체의 score가 떨어지면서 trajectory가 끊기는 fragmentation 문제를 일으켰다.
여기서 본질적 딜레마가 등장했다. Threshold를 높이면 가려진 객체가 사라져 missing detection이 늘었고, 낮추면 배경이 객체로 잘못 들어와 false positive가 폭증했다. 두 방향 모두 손해를 보는 trade-off였다.
저자들은 이 딜레마를 해결할 단순한 통찰을 제안했다. 핵심 아이디어 한 줄은 "low score box를 버리지 말고, tracklet과의 similarity로 검증해 객체와 배경을 구분하자" 였다. Low-score box가 기존 tracklet의 motion 예측과 잘 맞으면 그것은 가려진 진짜 객체이고, 어디에도 매칭되지 않으면 배경으로 제거하면 된다는 것이다.
논문 도입부에 인용된 Hegel의 명제 "이성적인 것은 실재하고, 실재하는 것은 이성적이다" 는 이 발상의 철학적 배경을 보여주었다. 즉, low confidence detection도 그 자리에 무엇인가 존재하기 때문에 신호가 잡힌 것이며, 단지 보이지 않는다는 이유로 부정해서는 안 된다는 메시지였다.

위 이미지는 동일 사람이 occlusion으로 score가 0.9 → 0.4 → 0.1까지 떨어지는 상황에서 기존 방법이 빨간 trajectory를 잃어버리는 반면, 모든 box를 검증한 BYTE는 motion 기반 IoU만으로 동일 identity를 끝까지 유지하는 모습을 보여주었다. 동시에 오른쪽 배경의 false positive box는 어느 tracklet과도 매칭되지 않아 자동으로 걸러졌다.
Background & Related Work
MOT에는 두 패러다임이 공존했다. Tracking-by-detection은 detection을 먼저 수행하고 그 결과를 association하는 방식이고, detection-by-tracking은 이전 프레임의 tracklet을 활용해 detection의 신뢰도 자체를 높이는 방식이었다. 본 논문은 전자에 속하지만 두 패러다임의 경계를 흐리는 효과를 가졌다.
Object detection의 발전이 곧 MOT의 발전이었다. DPM → Faster R-CNN → CenterNet → YOLOX로 이어진 흐름은 MOT의 정확도와 속도 한계를 직접 결정했다. 특히 YOLOX의 등장으로 single-stage anchor-free detector가 MOT 분야의 표준 backbone이 되었다.
Data Association은 유사도(similarity) 계산과 매칭 전략(matching strategy) 의 두 축으로 구성되었다. 유사도는 위치(IoU), 모션(Kalman filter), 외관(Re-ID feature)을 단독 또는 조합해 사용했고, 매칭 전략에는 Hungarian algorithm, cascaded matching, greedy assignment가 있었다.
대표 모델들의 association 철학은 다음과 같았다. SORT는 Kalman + IoU + Hungarian의 가장 단순한 구성이었고, DeepSORT는 여기에 별도의 Re-ID 모델을 cascaded matching으로 결합했다. MOTDT는 propagated box와 IoU를 함께 썼으며, FairMOT/JDE는 detection과 Re-ID를 한 네트워크에서 학습했다. QDTrack은 quasi-dense contrastive learning으로 association similarity 자체를 학습 목표로 만들었다.
기존 연구의 공통점은 모두 "어떻게 더 좋은 association method를 만들까" 에만 집중했다는 점이었다. 본 논문은 시점을 바꿔, detection box를 어떻게 활용하느냐가 association 성능의 상한선을 결정한다고 주장했다. 같은 association이라도 입력 box가 풍부해지면 결과가 달라진다는 관점이었다.
BYTE: Method
BYTE의 전체 파이프라인은 매우 짧고 직관적이었다. 매 프레임마다 detection을 수행하고, score를 기준으로 high/low로 분리한 뒤, 두 단계의 association을 거쳐 track을 갱신했다.
Algorithm 1: Pseudo-code of BYTE
Input : video V, detector Det, threshold τ
Output: Tracks T
T ← ∅
for frame f_k in V do
D_k ← Det(f_k)
D_high, D_low ← ∅, ∅
for d in D_k do
if d.score > τ : D_high ← D_high ∪ {d}
else : D_low ← D_low ∪ {d}
# predict new locations of tracks
for t in T : t ← KalmanFilter(t)
# 1st association (high score boxes)
Associate(T, D_high) using Similarity#1
D_remain ← unmatched high boxes
T_remain ← unmatched tracks
# 2nd association (low score boxes)
Associate(T_remain, D_low) using Similarity#2 (IoU only)
T_re-remain ← unmatched tracks → move to T_lost (keep 30 frames)
# initialize new tracks from remaining high boxes
for d in D_remain : T ← T ∪ {d}
return T
핵심 설계 1 — Two-stage association. 1차 매칭에서는 high score box로 안정적인 tracklet을 먼저 잇고, 2차 매칭에서 unmatched tracklet과 low score box를 다시 매칭해 occlusion으로 점수가 떨어진 객체를 복구했다. 이 두 단계 분리는 high score 매칭의 신뢰도를 보존하면서 low score box의 정보까지 회수할 수 있게 한 핵심 설계였다.
핵심 설계 2 — Similarity의 분리 사용. 1차 association의 Similarity#1은 IoU 또는 Re-ID 어느 쪽도 가능했지만, 2차 association의 Similarity#2는 반드시 IoU만 사용해야 했다. 그 이유는 low-score box가 대부분 심한 occlusion이나 motion blur를 동반하기 때문에, 그 위에서 추출된 Re-ID feature는 신뢰할 수 없는 노이즈가 되기 때문이었다. 위치 기반 IoU만이 안정적이었다.
핵심 설계 3 — Tracklet rebirth. 두 단계 매칭에서도 짝을 못 찾은 tracklet은 즉시 삭제하지 않고 큐에 30 frame 동안 보존했다. 이 기간 안에 다시 매칭되면 동일 identity를 회복했고, 30 frame이 지나면 비로소 제거했다. 이 단순한 메커니즘이 long-range identity 보존의 핵심이 되었다.
선형 할당의 거절 임계값 등 하이퍼파라미터는 다음과 같이 작성할 수 있었다. Detection box 와 tracklet
의 매칭 비용은
였고, 여기서
는 Kalman filter의 예측 box였다. 비용이 0.8을 초과하면 매칭을 거절했다.
ByteTrack은 이 BYTE association 알고리즘을 YOLOX-X detector와 결합한 구성체로 정의되었다. 별도의 Re-ID 네트워크, attention module, transformer 디코더 어떤 것도 사용하지 않았다. 단순함 자체가 디자인 결정이었다.
Experimental Setup
평가는 네 개의 대표 MOT 벤치마크에서 진행되었다. MOT17과 MOT20은 보행자 중심의 표준 벤치마크였고 (MOT20은 평균 170명이 한 화면에 등장하는 극단 혼잡 씬), HiEve는 다양한 카메라 뷰의 복잡 이벤트를, BDD100K는 8개 클래스의 자율주행 시나리오를 다뤘다.
평가 메트릭은 세 가지를 함께 보았다. MOTA는 FP, FN, IDs를 종합해 detection 품질에 가중을 두었고, IDF1은 identity 보존을 직접 측정해 association 품질을 반영했으며, HOTA는 둘을 균형 있게 결합한 신규 메트릭으로 최근 표준이 되었다.
학습 설정은 다음과 같았다. Detector는 YOLOX-X (COCO pre-trained), 학습 데이터는 CrowdHuman + MOT17 half, 80 epoch, V100 8장에서 12시간, 추론은 FP16 정밀도였다. SGD optimizer에 weight decay , momentum 0.9, 1 epoch warm-up 후 cosine annealing을 적용했다.
"Private detection" protocol은 자체 detector를 사용하는 트랙이고, ablation은 MOT17 학습 셋을 절반(half-split)으로 나눠 학습/검증으로 분리해 수행했다. 메인 벤치마크 결과는 외부에서 공개된 MOTChallenge test 서버 점수를 사용했다.
Ablation Studies & 핵심 분석
가장 먼저 검증한 것은 두 단계 association에서 어떤 similarity 조합이 최적인가였다. Table 1은 MOT17과 BDD100K에서 IoU와 Re-ID의 4가지 조합을 비교했다. MOT17에서는 (IoU, IoU) 조합이 76.6 MOTA / 79.3 IDF1 / IDs 159로 최적이었다. 2차 매칭에 Re-ID를 쓰면 IDs가 159 → 216으로 늘어 low score box의 Re-ID feature가 신뢰 불가능함을 정량적으로 보여주었다.
Table 2는 BYTE를 SORT, DeepSORT, MOTDT와 직접 비교했다. BYTE는 Re-ID 없이도 SORT 대비 MOTA 74.6 → 76.6, IDF1 76.9 → 79.3, IDs 291 → 159로 모든 면에서 우월했다. 더 놀라운 것은 Re-ID를 정교하게 쓰는 DeepSORT보다도 IDF1이 높았다는 점이다. 이는 단순한 Kalman filter만으로도 long-range association이 가능함을 입증했다.
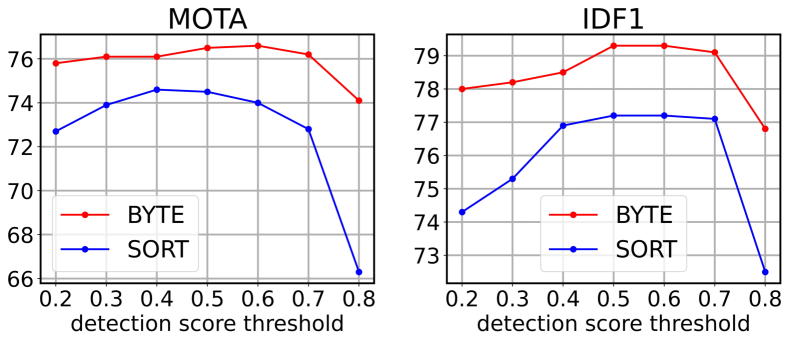
위 이미지는 threshold 를 0.2부터 0.8까지 변화시키며 두 tracker의 MOTA와 IDF1을 측정한 결과를 보여주었다. SORT는
가 떨어지면 false positive 폭증으로, 올라가면 missing detection으로 양쪽 끝에서 급락한 반면, BYTE는 거의 평평한 곡선을 그렸다. 이는 2차 association이
아래의 객체까지 회수해 threshold 선택에 둔감해진 결과였다.
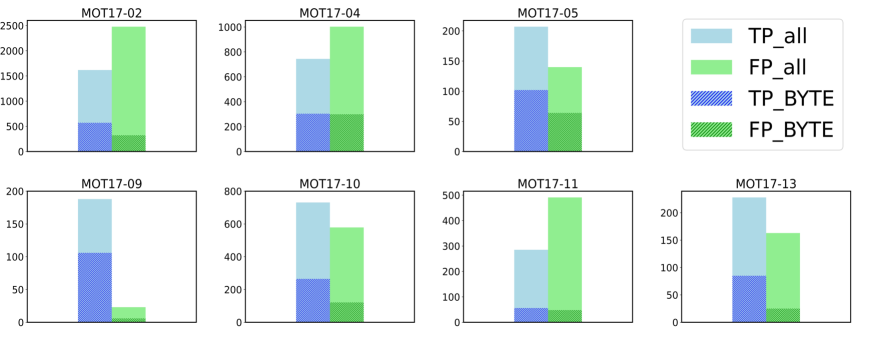
이 그림에서는 MOT17의 7개 시퀀스에 대해, low-score 영역 전체의 TP/FP 분포(연한 색)와 BYTE가 실제로 회수한 box의 TP/FP 분포(진한 색)를 함께 보여주었다. 모든 시퀀스에서 BYTE가 회수한 box는 TP 비중이 압도적으로 높았고 FP는 거의 잘려나갔다. tracklet과의 IoU 검증이 객체와 배경을 분리하는 효과적인 게이트였음을 시각적으로 확인할 수 있었다.
마지막 ablation은 BYTE의 범용성 검증이었다. JDE, CSTrack, FairMOT, TraDes, QuasiDense, CenterTrack, Chained-Tracker, TransTrack, MOTR 9개 tracker에 BYTE를 이식한 Table 3 결과는 인상적이었다. CenterTrack은 +9.8 IDF1, CTracker는 +5.8 IDF1, FairMOT/TransTrack/MOTR도 일관된 +1~+4 IDF1 향상을 보여 BYTE가 plug-and-play 모듈로 작동함을 입증했다.
Benchmark 결과
MOT17 test 셋(Table 4)에서 ByteTrack은 80.3 MOTA / 77.3 IDF1 / 63.1 HOTA / 30 FPS를 기록해 정확도와 속도 모두 1위였다. 2위인 ReMOT 대비 +3.3 MOTA, +5.3 IDF1, +3.4 HOTA의 큰 격차였고, 학습 데이터도 다른 SOTA(73K 이미지)보다 적은 29K 이미지만 사용했다.
MOT20 test 셋(Table 5)의 결과는 더 극적이었다. 평균 170명이 한 화면에 들어가는 극단 혼잡 환경에서 ByteTrack은 MOTA 68.6 → 77.8, IDF1 71.4 → 75.2, IDs 4209 → 1223 (71% 감소) 라는 차이를 만들어냈다. Occlusion이 일상인 시나리오에서 BYTE의 low-score box 회수 전략이 본질적 강건성을 발휘했다.
HiEve(Table 6)에서는 MOTA 40.9 → 61.7, IDF1 45.1 → 63.1로 2위 CenterTrack을 압도했다. BDD100K(Table 7)에서는 자율주행 환경의 큰 카메라 모션이 Kalman filter를 약화시켜 다른 데이터셋만큼 격차는 크지 않았으나, mMOTA 36.6 → 45.5(val), 35.5 → 40.1(test)로 여전히 1위를 차지했다.
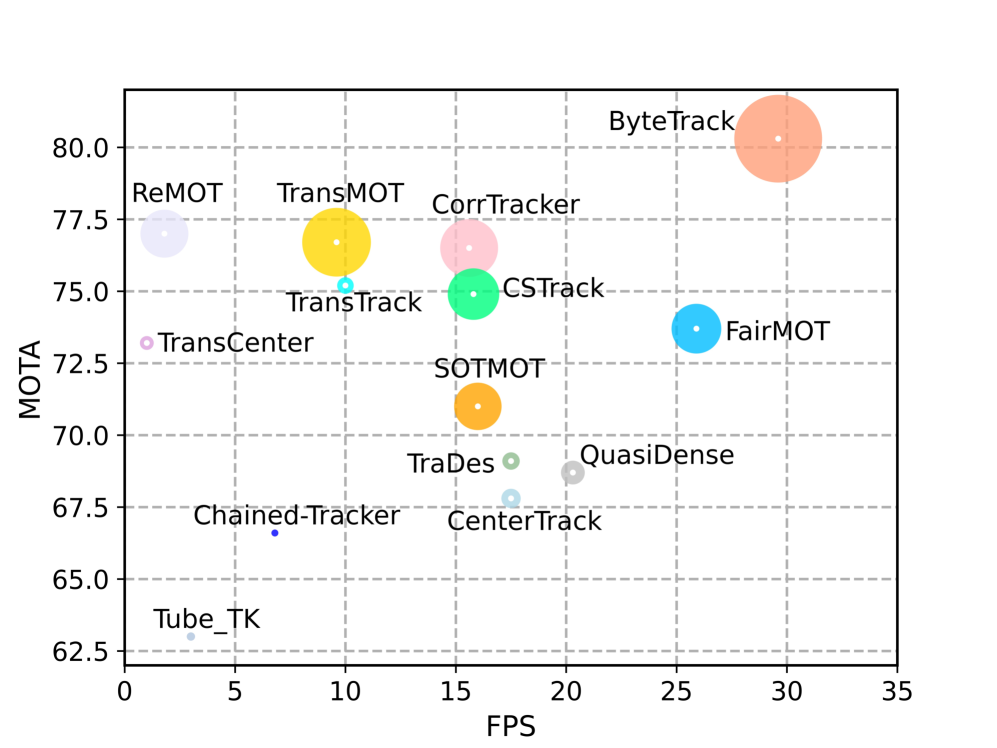
위 이미지는 MOT17 test 셋에서 ByteTrack이 우상단에 단독 위치한 모습을 보여주었다. x축은 FPS, y축은 MOTA, 원의 반지름은 IDF1을 의미했고 ByteTrack의 큰 원이 가장 빠르고 가장 정확한 동시에 IDF1까지 최고임을 한눈에 드러냈다. 다른 tracker들이 정확도와 속도 사이에서 trade-off하는 동안 ByteTrack은 양쪽 모두를 가져갔다.
단순성의 가치가 본 논문의 메시지였다. Re-ID network, attention, transformer 디코더 없이 Kalman filter + IoU 매칭 + 30 frame rebirth만으로 모든 메인 벤치마크에서 1위를 차지한 사실은, 복잡한 모듈 누적이 능사가 아니라는 것을 보여주었다.
비판적 분석 & Takeaway
강점은 분명했다. 첫째, 알고리즘이 단순해 구현/디버깅/배포가 쉬웠다. 둘째, BYTE는 9개의 서로 다른 tracker에 직접 이식 가능한 plug-and-play 모듈이었다. 셋째, 30 FPS의 실시간 속도와 SOTA 정확도를 동시에 달성한 균형이 실용성에서 압도적이었다.
약점과 의문도 있었다. Kalman filter는 등속 모션을 가정하기 때문에 BDD100K처럼 카메라 자체가 빠르게 움직이거나 frame rate가 낮은 환경에서는 본질적으로 깨졌고, 저자들도 BDD100K에서는 Kalman을 끄고 Re-ID로 보완해야 했다. 또한 의 하한을 어디로 잡을 것인지, 진짜 노이즈 box를 어떻게 사전에 거를 것인지에 대한 명시적 기준이 부족했다.
미해결 이슈도 남았다. 30 frame을 넘는 장기 occlusion 시 identity 보존은 여전히 풀리지 않았고, 비강체 객체나 군중 밀도가 극단으로 가는 경우 IoU 자체가 의미를 잃는 한계가 있었다. Tracklet interpolation은 사후 보정이지 근본 해법은 아니었다.
후속 연구 방향으로는 학습 기반 motion model로 Kalman을 대체하는 시도, BYTE의 "모든 검출을 검증하라" 철학을 segmentation/3D tracking/multi-camera로 확장하는 시도, low-score box의 uncertainty를 명시적으로 calibration하여 2차 매칭의 cost 함수를 재설계하는 방향이 자연스러워 보였다.
핵심 테이크어웨이 세 줄로 정리하면 다음과 같았다.
① "버리지 말고 검증하라" — low-score detection box는 노이즈가 아니라 occlusion된 객체의 신호일 가능성이 크다. ② Association의 상한은 detection 활용 방식이 결정한다 — 더 정교한 매칭이 아니라 더 풍부한 입력이 한계를 깬다. ③ 단순한 설계가 복잡한 모듈을 이긴다 — Kalman + IoU + rebirth 만으로 Re-ID/attention 기반 SOTA를 모두 추월했다.
'PaperReview' 카테고리의 다른 글
| RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (0) | 2026.05.14 |
|---|---|
| RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (1) | 2026.05.14 |
| Soft-NMS — Improving Object Detection with One Line of Code (0) | 2026.05.13 |
| Generative AI at Work (0) | 2026.05.12 |
| Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality (0) | 2026.05.06 |