Soft-NMS — Improving Object Detection with One Line of Code - 세미나 자료
저자: Navaneeth Bodla, Bharat Singh, R. Chellappa 외 1명
발행년도: 2017년
인용수: 2048회
논문 링크: https://www.semanticscholar.org/paper/53c0aa8d33d240197caff824a6225fb223c1181c
arXiv ID: 1704.04503
1. Problem & Motivation
Object detection 파이프라인의 마지막 관문은 늘 비-최대 억제(Non-Maximum Suppression, NMS)였다. RPN이 수천 개의 proposal을 뽑고, 분류 헤드가 클래스 점수를 매기고, 회귀 헤드가 박스를 다듬은 뒤에도, 같은 객체 위에 여러 박스가 중복으로 남는 현상은 피할 수 없었다. NMS는 이 중복을 정리해 최종 detection을 만들어내는 후처리 단계로, 무려 50년 가까이 detection 분야의 기본 도구로 자리잡아 왔다.
문제는 전통적 greedy NMS가 본질적으로 정보를 파괴한다는 점이었다. 최고 점수 박스 을 고른 뒤, 임계값
이상의 IoU를 가진 모든 박스를 점수 0으로 만들어 버리는 hard threshold 방식이기 때문이다. 인접한 객체가 실제로 존재해도, 박스가
과 충분히 겹쳤다는 이유만으로 ranked list에서 영구히 사라졌다.

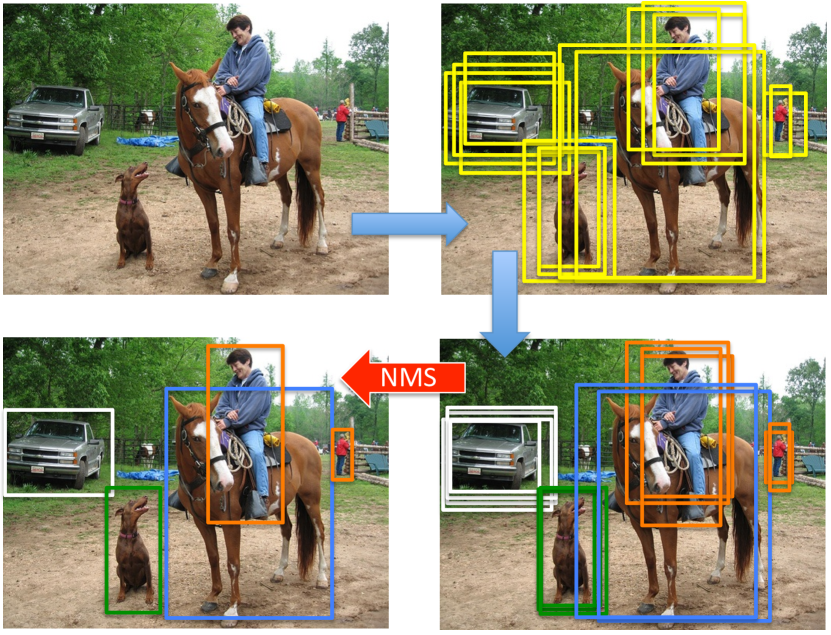
위 이미지는 빨간 박스(0.95)와 초록 박스(0.8)가 모두 진짜 말을 가리키지만, 두 박스의 IoU가 높아 전통적 NMS라면 초록 박스를 0점으로 죽여버린다는 상황을 보여주었다. 저자들은 여기서 "0으로 죽일 것인가, 0.4 정도로 살려둘 것인가"라는 단순한 질문을 던졌고, 이것이 Soft-NMS의 출발점이 되었다.
근본적인 trade-off도 명확했다. 를 낮추면 인접 객체를 miss할 확률이 올라가고,
를 높이면 false positive가 폭증했다. 게다가 COCO처럼 AP를 0.5에서 0.95까지 multi-threshold로 평균 내는 평가 기준에서는, 하나의
로 모든 overlap 구간을 만족시키는 것이 구조적으로 불가능했다.
핵심 아이디어는 한 줄로 정리되었다. "점수를 0으로 죽이지 말고, overlap에 비례해 부드럽게 감쇠시키자." 재학습도, 추가 하이퍼파라미터도, 새로운 네트워크도 필요하지 않은, 말 그대로 한 줄짜리 코드 수정이었다.
2. Background & Related Work
NMS는 1971년 Rosenfeld & Thurston의 edge detection 논문에서 처음 등장한 이래로, computer vision의 거의 모든 detection 문제에 등장해 왔다. edge thinning → feature point detection (Harris, SIFT) → face detection (Viola-Jones) → object detection (HOG, DPM, R-CNN 계열)로 이어지는 진화 과정에서, NMS는 형태만 바뀌었을 뿐 본질적인 메커니즘은 동일했다.
흥미로운 점은 2005년 Dalal & Triggs가 HOG 기반 보행자 검출에서 greedy NMS를 도입한 이후로, 무려 10년 이상 이 단계가 거의 손대지 않은 채로 남아 있었다는 사실이었다. R-CNN, Fast R-CNN, Faster R-CNN, R-FCN 모두 detection head 뒤에 동일한 greedy NMS를 붙였다.
학습 기반 대안이 없었던 것은 아니었다. Affinity propagation clustering (Rothe et al., 2014), QUBO (Rujikietgumjorn & Collins, 2013), Determinantal Point Process (Lee et al., 2016) 등은 NMS를 최적화 문제로 재정의하려 시도했다. 그러나 이들은 대부분 특정 도메인(보행자, salient object)에 특화되어 있었고, 일반적인 generic object detection AP 메트릭에서는 여전히 greedy NMS가 가장 강력한 baseline이었다.
위 이미지는 RPN이 카테고리 독립적인 proposal을 만든 뒤, classification/regression 네트워크가 각 proposal에 점수와 좌표 보정을 부여하고, 마지막으로 NMS가 최종 detection을 추려내는 표준 흐름을 보여주었다. NMS는 이 파이프라인의 가장 끝에 놓여 있으면서도, 전체 AP에 결정적 영향을 미치는 위치를 차지하고 있었다.
평가 메트릭의 변화도 NMS 재설계를 요구하는 배경이 되었다. PASCAL VOC 시절에는 IoU 0.5라는 단일 threshold만 보았지만, MS-COCO는 0.5부터 0.95까지 0.05 단위로 평균 낸 AP를 핵심 지표로 채택했다. 이는 localization 정밀도를 강하게 요구하는 평가 방식이었고, 하나의 hard threshold로 모든 overlap 구간을 만족시키는 것이 점점 어려워졌다.
3. Method: Soft-NMS 설계
저자들은 먼저 기존 NMS의 pruning 단계를 re-scoring function으로 재해석했다. 즉, NMS는 점수를 갱신하는 함수에 불과하다고 본 것이다.
이 수식은 binary indicator로서의 hard threshold를 명확히 드러냈다. 임계값을 넘는 순간 점수가 절벽처럼 0으로 떨어지는 구조였다.
Soft-NMS가 만족해야 할 설계 조건은 세 가지로 정리되었다. 첫째, 이웃 detection의 점수는 obvious false positive보다는 높게, 그러나 false positive rate를 키우지 않을 만큼 낮춰야 했다. 둘째, 낮은 로 이웃을 통째로 제거하면 높은
평가에서 miss rate가 폭증하므로 피해야 했다. 셋째, 높은
또한 multi-threshold AP를 떨어뜨리므로 피해야 했다.
가장 단순한 첫 시도는 linear weighting function이었다. overlap이 클수록 큰 페널티, 작을수록 작은 페널티를 부여하는 자연스러운 형태였다.
그러나 이 함수는 지점에서 불연속이라는 결함이 있었다. 임계값을 갓 넘는 순간 페널티가 갑자기 적용되어 ranked list가 급격히 흔들릴 수 있었다.
이를 해결하기 위해 Gaussian weighting function이 제안되었다. 모든 박스에 대해 연속적이고 부드럽게 작용하며, overlap이 0이면 페널티가 0이고 1에 가까워질수록 점수를 강하게 죽이는 형태였다.
핵심은 이 한 줄 교체로 끝난다는 점이었다.

위 이미지는 빨간색으로 표시된 기존 NMS의 hard threshold 라인을, 초록색의 single line re-scoring 로 교체하면 그대로 Soft-NMS가 된다는 점을 보여주었다. 학술적으로 가장 인상적인 부분은, 알고리즘의 큰 골격이 그대로 유지된다는 사실이었다.
Input: B = {b1,...,bN}, S = {s1,...,sN}, Nt
D ← {}
while B != empty:
m ← argmax S
M ← b_m
D ← D ∪ {M}; B ← B - {M}
for b_i in B:
# NMS:
# if iou(M, b_i) >= Nt: B ← B - b_i; S ← S - s_i
# Soft-NMS:
s_i ← s_i * f(iou(M, b_i))
return D, S
복잡도 분석도 명쾌했다. 각 iteration에서 모든 이웃 박스의 점수를 갱신하므로 한 step당 , 전체적으로
였다. 이는 기존 NMS와 정확히 동일한 복잡도였고, 추가 학습이나 별도 모델도 필요 없었다. Soft-NMS는 traditional NMS의 generalization으로, 기존 NMS는 binary weighting function을 가진 특수 케이스에 해당했다.
4. Experiments: 검증 전략과 결과
실험은 PASCAL VOC 2007 test와 MS-COCO test-dev / minival에서 진행되었다. detector는 당시 SOTA였던 Faster-RCNN, R-FCN, Deformable R-FCN을 모두 사용했고, 모든 모델은 재학습 없이 공개된 pretrained weight 위에서 NMS만 교체했다.
메인 결과는 단순하면서 강력했다. MS-COCO test-dev에서 R-FCN은 31.1 → 32.4 AP (+1.3%), Faster-RCNN은 24.4 → 25.5 AP (+1.1%) 개선되었다. PASCAL VOC 2007에서는 두 detector 모두 +1.7% AP 향상을 보였다. 특히 Deformable R-FCN + multi-scale testing 조합에 Soft-NMS를 더하자 single model SOTA가 39.8 → 40.9%로 갱신되었다.
| Method | AP[0.5:0.95] | AP@0.5 | Recall@100 |
|---|---|---|---|
| R-FCN | 31.1 | 52.5 | 43.6 |
| R-FCN + Soft-NMS (G) | 32.4 | 53.4 | 52.0 |
| Faster-RCNN | 24.4 | 45.7 | 37.1 |
| Faster-RCNN + Soft-NMS (G) | 25.5 | 46.6 | 45.3 |
| D-RFCN + MST | 39.8 | 62.4 | 52.9 |
| D-RFCN + MST + Soft-NMS (G) | 40.9 | 62.8 | 60.4 |
특히 주목할 만한 것은 Recall@100 지표의 대폭 향상이었다. R-FCN의 경우 43.6 → 52.0으로 8.4%p 상승했는데, 이는 Soft-NMS가 점수만 낮출 뿐 박스를 제거하지 않기 때문에 더 많은 true positive가 ranked list에 살아남았음을 의미했다.
흥미로운 비교는 proposal-based detector와 single-stage detector의 차이였다. SSD와 YOLOv2에서는 linear Soft-NMS의 개선이 +0.5%에 그쳤다. 저자들은 그 원인을 proposal-based detector가 본래 recall이 높기 때문에 Soft-NMS가 회복시킬 수 있는 박스가 더 많다는 점으로 해석했다. recall이 낮으면 살려낼 박스 자체가 없으므로 개선 여지가 줄어들었다.
Per-class 분석도 인상적이었다. zebra, giraffe, elephant, sheep, horse 같은 군집을 이루는 동물 클래스에서 3~6%의 큰 향상이 관찰되었고, 반대로 toaster, sports ball, hair drier처럼 한 이미지에 단독으로 등장하는 객체에서는 거의 개선이 없었다. 이는 Soft-NMS의 효과가 본질적으로 객체가 서로 겹쳐 있을 때 발휘된다는 사실을 명확히 보여주었다.
5. Sensitivity & 심층 분석
하이퍼파라미터 민감도는 Soft-NMS의 또 다른 강점을 드러냈다.
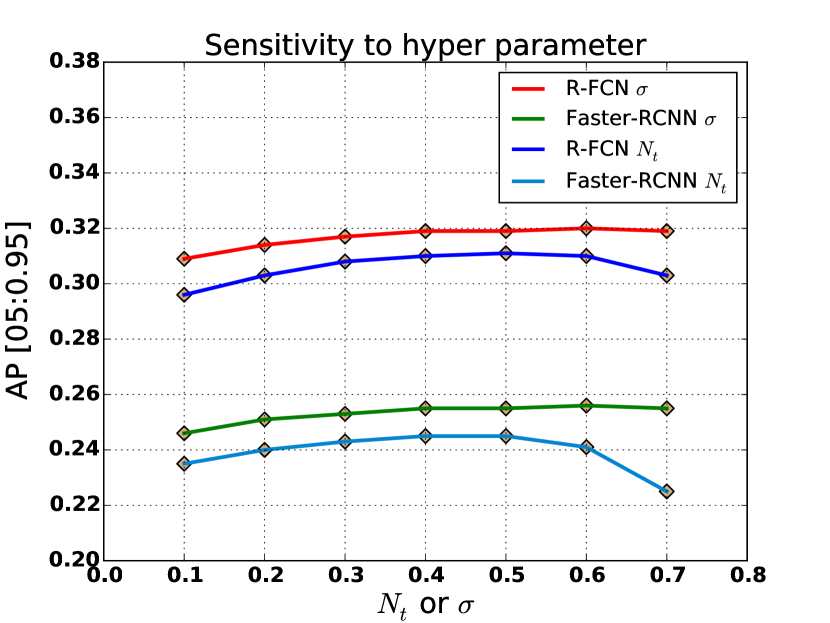
위 이미지는 동일한 R-FCN과 Faster-RCNN을 가지고 (NMS)와
(Soft-NMS)를 각각 0.1부터 0.7~0.8까지 변화시켰을 때의 AP[0.5:0.95] 곡선을 보여주었다. NMS는 0.3~0.6의 좁은 구간에서만 안정적이었고 그 바깥에서는 AP가 급락한 반면, Soft-NMS는 0.4~0.7 구간 전체에서 평탄한 곡선을 그리며 항상 NMS의 best score보다 약 1% 높은 위치에 머물렀다.
Localization 성능을 더 세밀하게 들여다보면 차이가 더 분명해졌다. Table 3을 보면, NMS는 를 0.3에서 0.7로 올리면 AP@0.7이 0.3823 → 0.3860으로 미미하게 올랐지만 AP@0.5는 0.5193 → 0.4894로 크게 떨어졌다. 반면 Soft-NMS는
를 키워도 낮은
에서의 AP가 거의 떨어지지 않으면서 높은
에서는 의미 있게 개선되었다.
핵심 통찰은 여기 있었다. 단일 값으로 multi-threshold AP의 모든 구간을 잘 처리할 수 있다는 점이 Soft-NMS의 multi-threshold AP 친화성을 만들어냈다. NMS는 어떤
를 골라도 한쪽
에서 손해를 보지만, Soft-NMS는 그렇지 않았다. 특히 높은
에서 Soft-NMS는 NMS보다 약 2% 높은 AP를 일관되게 보여주었다.
Precision-Recall 곡선도 메커니즘을 잘 설명해주었다. 낮은 recall 구간에서는 Soft-NMS가 점수를 낮추기만 하므로 precision 향상을 기대할 수 없었지만, 높은 recall 구간에서는 NMS가 0으로 죽여버린 박스들이 살아남아 precision이 의미 있게 개선되었다. 가 높을수록 "near miss" 케이스가 늘어나는데, 바로 그 지점에서 Soft-NMS가 가장 큰 이득을 냈다.
Qualitative 분석에서도 Soft-NMS의 동작은 직관적이었다. 한 이미지에서 여러 사람을 가로지르는 잘못된 wide 박스는, 작은 IoU로 여러 진짜 박스와 겹쳐 있어 점수가 여러 번 감쇠되며 자연스럽게 detection threshold 밑으로 내려갔다. 반대로 zebra나 horse처럼 객체가 나란히 서 있는 경우, NMS는 한쪽을 죽였지만 Soft-NMS는 양쪽을 모두 살려냈다.
6. 비판적 분석 & 정리
강점부터 정리하면 Soft-NMS의 매력은 명확했다. 첫째, 재학습이 전혀 필요 없었다. 기존 detector의 weight를 그대로 두고 inference 단계만 교체하면 끝났다. 둘째, 복잡도가 유지되어 추론 속도에 영향이 거의 없었다. 셋째, R-FCN, Faster-RCNN, Deformable R-FCN, SSD, YOLOv2 등 모든 detector에 plug-and-play로 적용 가능했다. 넷째, COCO 스타일의 multi-threshold AP에 구조적으로 잘 들어맞았다.
약점도 명확했다. 우선 Soft-NMS는 여전히 greedy 알고리즘이라는 한계가 있었다. 박스 간 전역 관계를 고려하지 않고, 최고 점수 박스를 차례로 뽑으며 지역적으로 페널티를 적용할 뿐이었다. 즉, globally optimal re-scoring은 아니었다. 또한 는 데이터셋과 detector마다 튜닝이 필요했으며, 논문의 권장값(0.5)이 모든 환경에서 최적이라는 보장은 없었다.
좀 더 근본적인 한계는 bounding box 좌표 정보를 전혀 활용하지 않는다는 점이었다. Soft-NMS는 오직 점수만 수정할 뿐, 박스의 위치 자체를 보정하지는 않았다. 같은 객체에 대한 두 박스의 평균을 내거나, IoU 기반 회귀를 통해 더 좋은 박스를 만들 가능성은 열려 있었다.
자연스럽게 떠오르는 의문은 다음과 같았다. 박스 좌표 자체를 보정하는 방향과 결합하면 어떨까? 학습 가능한 NMS와 통합하면 어떻게 될까? 실제로 이런 질문은 Soft-NMS 이후 학계의 후속 연구 흐름과 정확히 맞닿아 있었다. Learning NMS(Hosang et al.), Relation Networks for Object Detection, IoU-Net, 그리고 궁극적으로 NMS 자체를 제거한 end-to-end DETR로 이어지는 계보가 바로 그것이었다.
세미나의 테이크어웨이를 세 줄로 압축하면 다음과 같았다. 첫째, hard threshold는 본질적으로 정보 손실을 야기한다. 이진 결정은 ranked list에서 박스를 영구히 제거해버린다. 둘째, 연속적 score decay는 ranking 정보를 보존하면서도 false positive를 효과적으로 억제한다. Gaussian penalty는 그 단순한 구현체였다. 셋째, 단순함이 곧 채택률이다. Soft-NMS의 "one line of code" 철학은 재학습도, 추가 학습 파라미터도 없는 변경만으로 detection 분야 전체에 빠르게 흡수되었고, 그 점이야말로 이 논문이 2천 회 이상 인용된 가장 강력한 이유였다.
'PaperReview' 카테고리의 다른 글
| RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (1) | 2026.05.14 |
|---|---|
| ByteTrack: Multi-Object Tracking by Associating Every Detection Box (0) | 2026.05.13 |
| Generative AI at Work (0) | 2026.05.12 |
| Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality (0) | 2026.05.06 |
| Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2026.05.06 |