RF-DETR Object Detection vs YOLOv12 : A Study of Transformer-based and CNN-based Architectures for Single-Class and Multi-Class Greenfruit Detection in Complex Orchard Environments Under Label Ambiguity - 세미나 자료
저자: Sapkota, Ranjan, Cheppally, Rahul Harsha, Sharda, Ajay 외 1명
발행년도: 2025년
인용수: None회
논문 링크: https://arxiv.org/abs/2504.13099
arXiv ID: 2504.13099
Problem & Motivation
복잡한 과수원 환경에서 미성숙 녹색 과일(immature greenfruit) 을 검출하는 일은 단순한 객체 검출 문제로 보이지만, 실제로는 컴퓨터 비전이 직면하는 가장 까다로운 시나리오 중 하나로 꼽혔다. 사과의 표면과 잎의 색이 거의 동일한 녹색 톤을 공유하며, 군집(clustering)으로 인한 occlusion, 강한 햇빛 그림자, 화면 경계에서의 truncation까지 겹치면서 모델이 "이게 과일인가 잎인가"를 단정하기 어려운 상황이 빈번하게 발생했다.
저자들은 이 문제를 label ambiguity 라는 키워드로 명시적으로 끌어올렸다. 사람조차도 occlusion이 심한 과일을 'occluded'로 볼지 'non-occluded'로 볼지 일관되게 라벨링하기 어렵다는 점이, 검출 모델 성능의 본질적 천장이 된다고 주장했다.
기존 접근의 한계도 분명했다. CNN 기반 YOLO 계열은 빠르고 가벼웠지만 전역 문맥(global context) 을 충분히 포착하지 못해 군집·occlusion 상황에서 자주 실패했다고 지적했다. 반대로 DETR 계열 초창기 모델은 수렴이 너무 느리고 계산량이 컸으며, 최근 등장한 RF-DETR 도 YOLOv11까지만 비교되어 최신 YOLOv12 와의 직접 대결은 공백 상태로 남아 있었다고 설명했다.
이 논문의 핵심 아이디어는 한 줄로 요약되었다. 동일한 데이터셋과 하이퍼파라미터 조건에서 RF-DETR(Transformer)과 YOLOv12(CNN) 를 single-class 및 multi-class greenfruit detection 과제로 정면 비교해, label ambiguity 환경에서 두 패러다임 중 어느 쪽이 우위인지를 실증적으로 가리겠다는 것이었다.
Background: Object Detection 6대 패러다임과 두 주역
저자들은 객체 검출 연구사를 6가지 흐름으로 정리했다. CNN 기반, Transformer 기반, Vision-Language Model(VLM), Hybrid, Sparse Coding, Traditional 접근으로 분류하면서, 이 중 실질적으로 SOTA를 이끄는 두 축이 CNN과 Transformer 계열임을 강조했다.
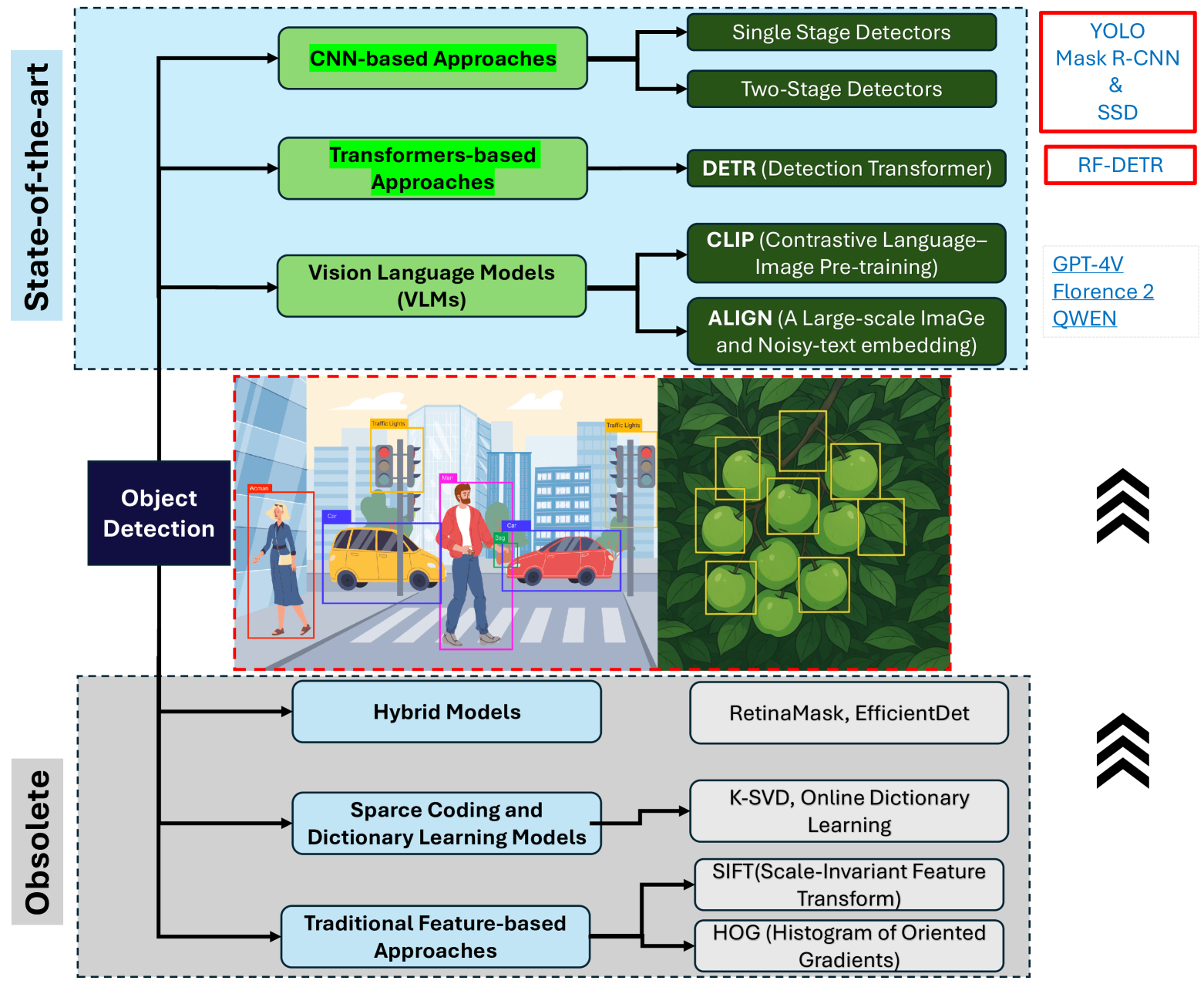
위 이미지는 현대 객체 검출 알고리즘이 어떤 계보로 분기되어 왔는지를 한눈에 보여주었다. CNN 계보가 R-CNN에서 YOLO 시리즈로 이어지는 한편, Transformer 계보는 DETR에서 RF-DETR까지 빠르게 진화해 왔다는 점이 시각적으로 드러났다.
CNN 계열은 R-CNN family → SSD → RetinaNet → EfficientDet → YOLO 시리즈로 이어지면서 점차 속도와 정확도의 균형 을 정교하게 다듬어 왔다고 설명했다. 특히 YOLO 시리즈는 anchor-free, dynamic label assignment 등 Transformer의 장점을 흡수하며 매 버전마다 갱신을 거듭했다.
Transformer 계열은 DETR이 anchor·NMS-free 패러다임을 열었지만 수렴 속도가 문제였고, 이를 Deformable DETR → RT-DETR → Co-DETR → DINO가 단계적으로 보완해왔다고 정리했다. RF-DETR 은 이 흐름의 가장 최근 결과물로, DINOv2 backbone과 deformable cross-attention을 결합해 실시간성과 정확도를 동시에 잡으려는 시도였다고 설명했다.
특히 흥미로운 부분은 label ambiguity 의 정의였다. 저자들은 농업 도메인에서 라벨이 모호해지는 네 가지 실제 사례를 제시했다. 첫째 과일이 빽빽하게 뭉친 클러스터, 둘째 잎 그림자로 인한 조명 왜곡, 셋째 잎과 과일이 거의 같은 색으로 보이는 foliage mimicry, 넷째 화면 경계에서 잘려나가는 truncation이 그것이었다.
Dataset & Problem Setup
데이터 수집은 미국 워싱턴주 Prosser의 'Scifresh'(Jazz) 사과 과수원 에서 진행되었다. UR5e 로봇팔에 Intel RealSense D435i RGB-D 카메라를 장착해 일관된 시점에서 이미지를 수집했고, 시기는 2024년 5월로 잡았다. 이 시점은 농가가 적과(thinning)를 결정하기 직전이라, 실제 농업 자동화 의사결정과 직결되는 가장 중요한 단계였다.

이 그림에서 데이터 수집 위치, 로봇 기반 촬영 셋업, 그리고 두 모델의 비교 방법론이 한 흐름으로 정리된 것을 확인할 수 있었다. 단순히 인터넷에서 긁은 이미지가 아니라 동일 환경·동일 시점에서 통제된 조건으로 수집되었다는 점이 실험 신뢰도의 근거가 되었다.
데이터 규모는 857장의 이미지와 4,125개의 객체 라벨 이었다. 절대 규모는 크지 않았지만, 동일 품종·동일 시기·동일 센서에서 수집된 controlled dataset이라는 점에서 모델 비교 실험에는 충분한 통제력을 제공했다고 평가했다.
라벨링은 두 가지 방식으로 수행되었다. Single-class 는 모든 greenfruit을 하나의 클래스로 묶어 baseline 검출 성능을 측정했고, Multi-class 는 90% 이상 가시성을 기준으로 occluded와 non-occluded로 분할했다. 이 분할은 단순 검출이 아니라 "과일이 얼마나 가려졌는가" 를 모델이 구분할 수 있는지를 검증하려는 의도였다.
저자들은 이 multi-class 설정이야말로 label ambiguity가 노골적으로 드러나는 지점이라고 주장했다. 90%라는 기준 자체가 인간 어노테이터의 주관에 노출되어 있고, 그 모호함이 두 아키텍처의 일반화 능력을 갈라놓는 시험대가 되었기 때문이다.
Method: 두 아키텍처의 설계 철학 비교
두 모델은 같은 목표를 향해 정반대의 길을 걸어왔다. 이 차이를 이해하는 것이 결과 해석의 출발점이 되었다.
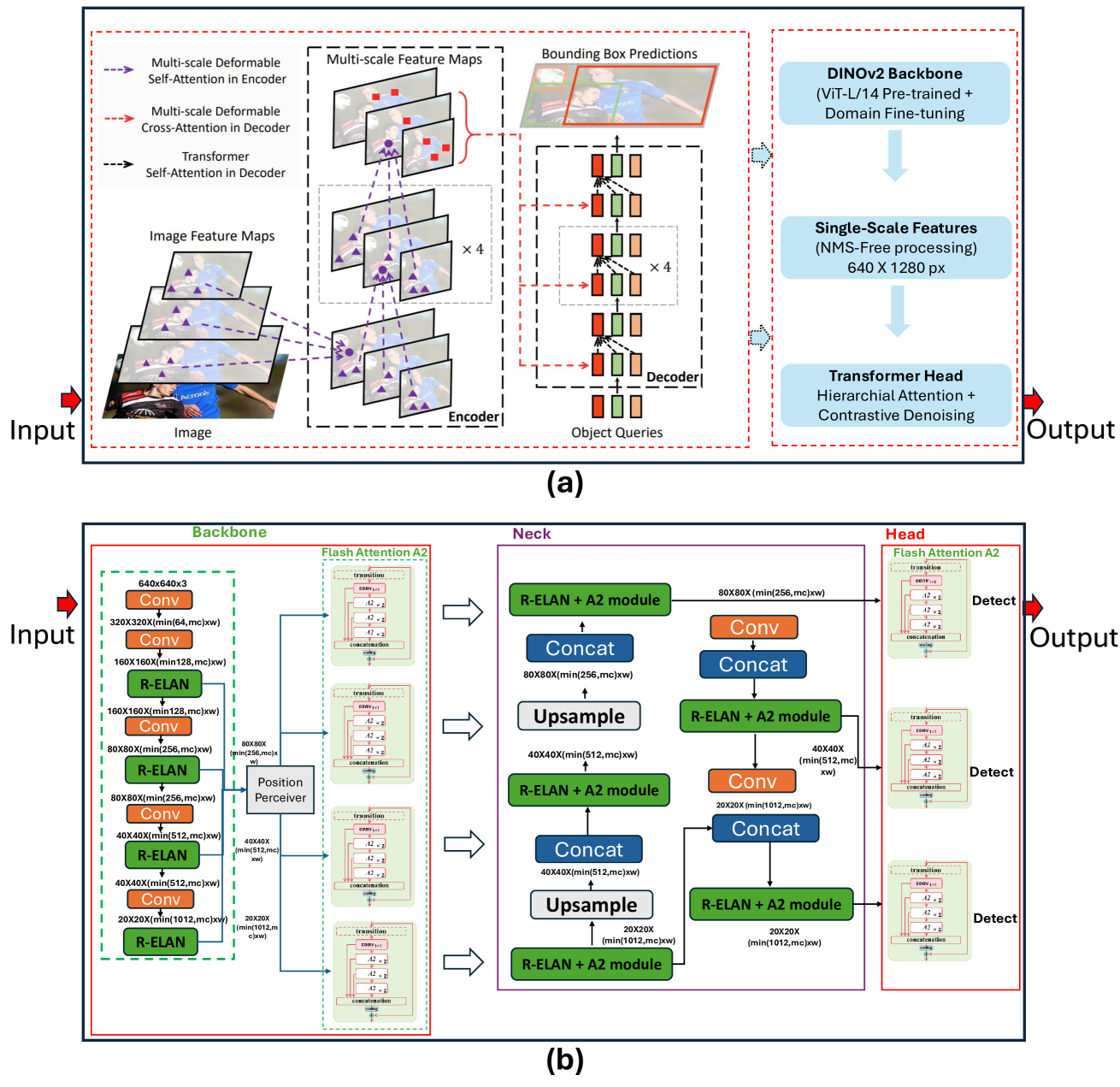
위 이미지는 RF-DETR이 DINOv2 backbone에서 추출된 단일 스케일 feature를 Transformer encoder-decoder로 흘리는 구조인 반면, YOLOv12는 R-ELAN backbone과 area attention을 결합한 multi-stage CNN 흐름이라는 점을 명확히 보여주었다. 즉 한쪽은 attention 중심, 다른 쪽은 convolution 중심 의 설계 철학을 끝까지 밀고 나간 셈이었다.
RF-DETR 은 DINOv2 backbone에 deformable cross-attention을 결합해 global context 를 포착하도록 설계되었다. anchor와 NMS가 없는 end-to-end set prediction 구조이며, single-scale feature extraction을 채택해 연산 효율을 끌어올렸다. 특히 contrastive denoising 과 collaborative label assignment 는 ambiguous한 객체 경계에서도 학습 안정성을 유지하도록 돕는 핵심 장치라고 설명했다.
YOLOv12 는 다른 방향으로 진화했다. R-ELAN backbone과 7×7 separable convolution 을 도입해 positional encoding을 대체하면서 파라미터를 약 60% 줄였다. 그러면서도 attention의 장점을 포기하지 않기 위해 FlashAttention 기반 area attention 을 도입했는데, feature map을 4등분해 부분 attention을 수행함으로써 메모리를 약 40% 절감했다고 보고했다.
두 모델의 본질적 trade-off는 명확했다. RF-DETR은 global context와 표현력, YOLOv12는 국소 특징(local feature)과 엣지 효율성 을 각각 극단까지 추구한 설계였다.
손실 함수도 철학을 그대로 반영했다. RF-DETR은 CrossEntropy + L1 + GIoU + contrastive denoising 항으로 구성된 set-level 학습을 수행했고, 매칭은 Hungarian assignment 기반이었다. 단순화된 형태는 다음과 같이 표기되었다.
반면 YOLOv12는 anchor-free 구조 위에 dynamic label assignment를 결합해, 매 배치에서 객체-앵커 매칭을 적응적으로 조정하는 방식이었다. 핵심 평가지표인 mAP 는 두 모델 모두 동일한 정의로 측정되었다.
Training Protocol & Evaluation Metrics
저자들은 공정한 비교 를 가장 중요한 설계 원칙으로 내세웠다. 모든 학습은 RTX A5000 GPU 단일 환경에서 진행되었고, 입력 해상도 640×640, FP32 정밀도, 배치 크기 16으로 통일했다. optimizer와 데이터 split도 동일하게 맞추었다.
다만 한 가지 차이가 남았다. RF-DETR은 single-class 50 epoch, multi-class 100 epoch으로 학습했고, YOLOv12는 모든 설정에서 100 epoch을 돌렸다. 저자들은 이것이 RF-DETR이 더 빠르게 수렴한다 는 경험적 사실을 반영한 선택이라고 설명했지만, 이 차이는 뒤에서 다룰 공정성 논쟁의 불씨가 되기도 했다.
YOLOv12는 N(Nano), L(Large), X(Extra-Large) 세 가지 variant를 모두 포함했다. 이는 모델 크기에 따른 정확도-속도 trade-off가 농업 엣지 디바이스 배포 시 결정적이라는 점을 반영한 설계였다.
평가 메트릭은 다양하게 설정되었다. Precision, Recall, F1, mAP@50, mAP@50:95, mIoU가 각각 측정되었는데, 특히 mAP@50과 mAP@50:95의 분리는 중요했다. mAP@50은 "잘 찾았는가"를, mAP@50:95는 "얼마나 정확하게 박스를 그렸는가" 를 평가하기 때문이었다.
Multi-class 설정에서는 한 가지 미묘한 정의가 추가되었다. occluded와 non-occluded를 혼동한 경우를 False Positive로 처리 한 것이다. 이 정의는 RF-DETR이 occlusion 미세 분류에 약할 경우 점수를 크게 깎아내릴 수 있다는 점에서, 결과 해석에 결정적인 영향을 미쳤다.
Results & Analysis: 무엇이 증명되었는가
Single-class 결과는 흥미로운 분기를 보여주었다. RF-DETR이 mAP@50 0.9464 로 최고 성능을 기록한 반면, YOLOv12N은 mAP@50:95 0.7620 으로 strict한 localization 평가에서는 우위를 보였다. 같은 데이터셋에서 메트릭에 따라 승자가 갈린 것이다.
이 차이는 두 모델의 본성을 그대로 드러냈다. RF-DETR은 "과일이 어디 있다" 는 거시적 판단에 강했고, YOLOv12는 "박스가 얼마나 정확하다" 는 미시적 정렬에 강했다.

위 이미지는 dense cluster와 화면 경계 truncation 상황에서 RF-DETR이 occluded 라벨을 더 일관되게 회수하는 반면, YOLOv12는 명확하게 보이는 객체에는 강하지만 가려진 객체를 자주 놓치는 패턴을 시각적으로 보여주었다. label ambiguity가 가장 격렬해지는 군집 구역에서 두 패러다임의 차이가 뚜렷이 드러난 사례였다.
Multi-class 결과에서는 RF-DETR의 우위가 더 명확해졌다. RF-DETR이 mAP@50 0.8298 로 최고치를 기록한 반면 YOLOv12L은 mAP@50:95 0.6622 에 머물렀다. occluded/non-occluded 분류는 본질적으로 모호한 시각 단서를 종합해야 하는 과제였고, 이때는 global context를 보는 Transformer가 명백히 유리했다.
학습 동역학도 의미심장했다. RF-DETR은 20 epoch 이하에서 이미 수렴 하는 양상을 보였는데, 이는 사전학습된 DINOv2 backbone의 표현력이 농업 도메인에 빠르게 전이된 결과로 해석되었다. 반면 YOLOv12는 점진적으로 성능을 끌어올렸지만 최종 수렴 지점이 더 낮았다.
결론적으로 본 논문이 증명한 바는 다음과 같이 정리되었다. 복잡하고 모호한 공간 인식에는 global context를 가진 RF-DETR이 우세 했고, strict한 IoU 평가와 엣지 효율성이 요구되는 시나리오에서는 YOLOv12가 여전히 강력 했다. 즉 "어떤 모델이 낫다" 가 아니라 "어떤 메트릭과 배포 조건에서 누가 낫다" 가 본 연구의 진짜 결론이었다.
비판적 분석 & 정리
이 논문의 강점은 분명했다. 동일한 데이터·하드웨어·하이퍼파라미터 조건 에서 두 SOTA 모델을 정면 비교했고, label ambiguity를 단순히 언급한 것이 아니라 데이터셋 설계와 평가 정의에 명시적으로 반영했다. YOLOv12를 N/L/X 세 variant로 나눠 모델 크기 효과까지 분리해낸 점도 실용적 가치가 높았다.
그러나 약점도 적지 않았다. 단일 품종('Scifresh') · 단일 사이트 · 단일 시기 라는 점에서 일반화 가능성이 제한적이었고, FPS와 latency 같은 실측 배포 메트릭이 부재 했다. RF-DETR-Large variant가 비교에 포함되지 않은 점, 90% 가시성 기준이 주관적이라는 점도 약점이었다.
재현성 측면에서도 의문이 남았다. RF-DETR 50 epoch vs YOLOv12 100 epoch 의 학습량 차이가 "공정한 비교"의 정의에 부합하는지, 데이터셋이 외부에 공개되어 검증 가능한지 등이 명확히 다뤄지지 않았다.
후속 연구 방향은 자연스럽게 도출되었다. 다른 작물·계절·조명 조건으로의 일반화 검증, semi-supervised learning을 통한 label ambiguity 완화, 엣지 디바이스에서의 실측 latency 비교, 그리고 RF-DETR-Large vs YOLOv12X의 동급 비교 가 필요하다고 정리했다.
이 논문의 핵심 테이크어웨이는 세 줄로 압축되었다. 첫째, 복잡하고 모호한 환경에서는 Transformer의 global context가 우위에 있다. 둘째, strict한 localization과 엣지 효율은 여전히 CNN 기반 YOLO의 강점이다. 셋째, "어떤 모델이 더 좋은가" 라는 질문은 틀렸으며, "어떤 메트릭과 배포 조건에서 누가 더 좋은가" 라는 질문이 본 논문이 우리에게 남긴 진짜 화두였다.
'PaperReview' 카테고리의 다른 글
| Prompt-based Adaptation in Large-scale Vision Models: A Survey (0) | 2026.05.21 |
|---|---|
| Recognition in Terra Incognita (0) | 2026.05.20 |
| RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (0) | 2026.05.14 |
| RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (1) | 2026.05.14 |
| ByteTrack: Multi-Object Tracking by Associating Every Detection Box (0) | 2026.05.13 |