랜덤포레스트의 부트스트래핑 분할
- 여러개의 데이터세트를 중첩되게 분리하는 것
- 배깅 → bootstrap aggregation의 준말
사이킷런 랜덤포레스트 하이퍼 파라미터
- n_estimators
- 랜덤포레스트에서 결정트리의 개수를 지정. 늘릴수록 학습수행시간이 오래걸림. 디폴트 10개
- max_features
- 결정트리에 사용된 max_features파라미터와 같음.
랜덤 포레스트 실습
import pandas as pd
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] >0 else x[0] , axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_df
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0, max_depth=8)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))
랜덤 포레스트 정확도: 0.9196
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [8, 16, 24],
'min_samples_leaf' : [1, 6, 12],
'min_samples_split' : [2, 8, 16]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
최적 하이퍼 파라미터:
{'max_depth': 16, 'min_samples_leaf': 6, 'min_samples_split': 2}
최고 예측 정확도: 0.9165
rf_clf1 = RandomForestClassifier(n_estimators=100, min_samples_leaf=6, max_depth=16,
min_samples_split=2, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
예측 정확도: 0.9260
부스팅(Boosting)
- 여러개의 약한 학습기를 순차적으로 예측하면서 ‘가중치 부여’를 통해 오류를 개선해나가면서 학습하는 방식
- AdaBoost와 그래디언트 부스트가 있음
사이킷런 GBM 주요 하이퍼 파라미터 및 튜닝
- loss
- 경사하강법에서 사용할 비용 함수를 지정
- learning_rate
- GBM이 학습을 진행할때마다 적용하는 학습률
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))
GBM 정확도: 0.9389
GBM 수행 시간: 993.0 초
# GridSearchCV를 이용하여 최적으로 학습된 estimator로 predict 수행.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
XGBoost 개요
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- CPU병렬처리, GPU지원
- 다양한 성능 향상 기능
- 규제(Regularization) 기능 탑재
- TreePruning
- 다양한 편의 기능
- 조기 중단(Early Stopping)
- 자체 내장된 교차 검증
- 결손값 자체 처리
XGBoost 하이퍼 파라미터
- Learning_rate
- GBM의 학습률과 같은 파라미터.
- min_child_weight
- 결정트리의 min_child_leaf와 유사, 과적합 조절용
- max_depth
- 결정트리의 max_depth와 동일. 트리의 최대깊이
- subsample
- GBM의 subsample과 동일. 과적합 제어 데이터샘플 비율 지정
- reg_lambda
- L2 규제 적용값. 기본값은 1. 과적합 제어
- reg_alpha
- L1 규제 적용값. 기본값은 0 . 과적합 제어
- colsample_bytree
- GBM의 max_features. 트리 생성에 필요한 피처를 임의로 샘플링
- scale_pos_weight
- 비대칭 클래스로 구성된 데이터세트의 균형을 유지하기 위한
- gamma
- 리프 노드를추가적으로 결정할 최소 손실 감소 값
- 값이 클수록 과적합 감소 효과
- 조기 중단 기능
XGBoost를 이용한 위스콘신 유방암 예측(파이썬 Native XGBoost 사용)
- 데이터 셋 로딩
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# xgboost 패키지 로딩하기
import xgboost as xgb
from xgboost import plot_importance
import warnings
warnings.filterwarnings('ignore')
dataset = load_breast_cancer()
features= dataset.data
labels = dataset.target
cancer_df = pd.DataFrame(data=features, columns=dataset.feature_names)
cancer_df['target']= labels
cancer_df.head(3)
- 학습과 예측 데이터 세트를 DMatrix로 변환
- Dmatrix는 넘파이 array, DataFrame에서도 변환 가능
# 학습, 검증, 테스트용 DMatrix를 생성. dtr = xgb.DMatrix(data=X_tr, label=y_tr) dval = xgb.DMatrix(data=X_val, label=y_val) dtest = xgb.DMatrix(data=X_test , label=y_test) - 하이퍼 파라미터 설정
params = { 'max_depth':3,
'eta': 0.05,
'objective':'binary:logistic',
'eval_metric':'logloss'
}
num_rounds = 400
- 주어진 하이퍼파라미터와 early stopping 파라미터를 train()함수의 파라미터로 전달하고 학습
# 학습 데이터 셋은 'train' 또는 평가 데이터 셋은 'eval' 로 명기합니다.
eval_list = [(dtr,'train'),(dval,'eval')] # 또는 eval_list = [(dval,'eval')] 만 명기해도 무방.
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params = params , dtrain=dtr , num_boost_round=num_rounds , \\
early_stopping_rounds=50, evals=eval_list )
- predict()를 통해 예측 확률값을 반환하고 예측 값으로 변환
pred_probs = xgb_model.predict(dtest)
print('predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])
- `get_clf_eval()을 통해 예측 평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
get_clf_eval(y_test , preds, pred_probs)
오차 행렬
[[35 2]
[ 2 75]]
정확도: 0.9649, 정밀도: 0.9740, 재현율: 0.9740, F1: 0.9740, AUC:0.9965
- Feature Importance 시각화
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)
사이킷런 Wrapper XGBoost 개요 및 적용
- 사이킷런 래퍼 클래스 임포트, 학습 및 예측(DMatrix 쓸필요 없음)
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
# Warning 메시지를 없애기 위해 eval_metric 값을 XGBClassifier 생성 인자로 입력. 미 입력해도 수행에 문제 없음.
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, eval_metric='logloss')
xgb_wrapper.fit(X_train, y_train, verbose=True)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
- early stopping을 50으로 설정하고 재학습/예측/평가
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3)
evals = [(X_tr, y_tr), (X_val, y_val)]
xgb_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric="logloss",
eval_set=evals, verbose=True)
ws50_preds = xgb_wrapper.predict(X_test)
ws50_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
4-7 LightGBM
사이킷런 래퍼 LightGBM 클래스
- LGBMClassifier: 분류를 위한 클래스
- LGBMRegressor: 회귀를 위한 클래스
LightGBM 장점
- XGBoost 보다 학습에 걸리는 시간이 훨씬 적음
- 메모리 사용량도 상대적으로 적음
- 카테고리형 피처의 자동 변환, 최적 분할 (원-핫 인코딩 없이도 카테고리형 피처를 최적으로 변환하고, 이에 따른 노드 분할)
- 대용량 데이터에 대한 뛰어난 예측 성능 및 병렬 컴퓨팅 제공
- 최근에는 GPU까지 지원XGBoost와 예측 성능에 큰 차이가 없음, 오히려 기능상의 다양성은 LightGBM이 더 많음
LightGBM 단점
- 적은 데이터 세트에 적용시 과적합 발생이 쉬움
다른 GBM 계열과 차이점
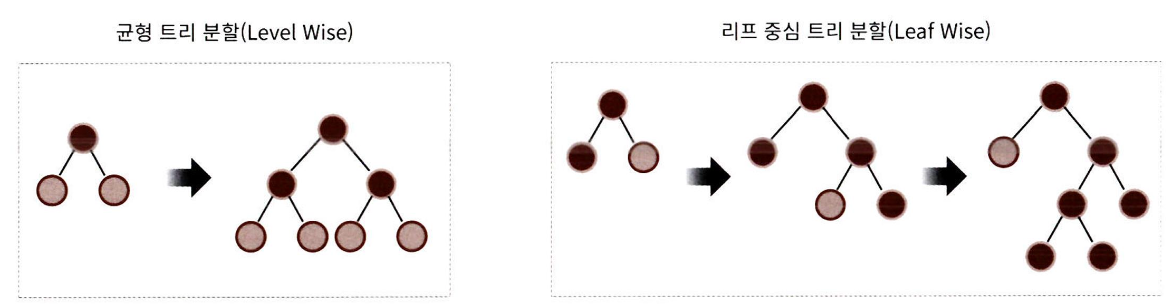
LightGBM은 일반 GBM 계열의 균형 트리 분할 방식(Level Wise)과 달리 리프 중심 트리 분할 (Leaf Wise) 방식을 사용
➡️ 트리의 균형을 맞추지 않고, 최대 손실값 (max delta loss)를 가지는 리프노드를 지속적으로 분할하여 트리 깊이가 깊고 비대칭적인 트리를 생성
!https://velog.velcdn.com/images/gchaewon/post/55ff3f56-9b51-43cb-a9bb-d5d121fb2e17/image.png
{kind=link}
LightGBM의 구현 사상
최대 손실 값을 지속적으로 분할하기 때문에, 균형 트리분할 방식보다 예측 오류 손실을 최소화할 수 있음
LightGBM 하이퍼 파라미터
XGBoost와 많은 부분이 유사함
⭐️ 리프 노드가 게속 분할되며 트리 깊이가 깊어지므로, max_depth 등 관련 하이퍼 파라미터 설정이 필요
주요 파라미터
- num_iterations[defaut = 100]: 반복 수행하려는 트리 개수 지정
- 클 수록 예측 성능 높아짐, 너무 큰 경우 과적합 (==n_estimators)
- learning_rate[default = 0.1]: 0~1사이 값 지정, 부스팅 스템 반복 수행할 때 업데이트 되는 학습률 값 (n_estimators를 크게, learning_rate를 작게해서 예측 성능 향상)
- max_depth[default = -1]: 0보다 작은 값 지정시 깊이 제한 없음
- min_data_in_leaf[default = 20]: 결정 트리의 min_samples_leaf와 같은 파라미터, 리프노드가 되기 위해 최소한으로 필요한 레코드 수로 과적합 제어 (== min_child_samples)
- num_leaves[default = 31]: 하나의 트리가 가질 수 있는 최대 리프 개수
- boosting[default = gbdt]: 부스팅 트리를 생성하는 알고리즘
- gbdt: 일반적인 그래디언트 부스팅 결정 트리
- rf: 랜덤 포레스트
- bagging_fraction[default = 1.0]: 트리가 커져서 과적합 하는 것을 제어, 데이터 샘플링 비율을 지정 (==subsample)
- feature_fraction[default = 1.0]: 개별 트리를 학습할 때마다 무작위로 선택하는 피처의 비율, 과적합을 막기 위해 사용
- (GBM의 max_features와 유사)
- lambda_l2[default = 0.0]: L2 regulation 제어를 위한 값, 값이 클수록 과적합 감소 효과 (== reg_lambda)
- lambda_l1[default = 0.0]: L1 regulation 제어를 위한 값, 값이 클수록 과적합 감소 효과 (== reg_alpha)
Learning Task 파라미터
- objective: 최솟값을 가져야 할 손실함수 정의 (Xgboost의 파라미터와 동일), 분류 (회귀, 다중 클래스, 이진) 에 따라 손실함수 지정
하이퍼 파라미터 튜닝 방안
num_leaves를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하여 모델의 복잡도를 줄이는 것이 기본 튜닝 방안
- num_leaves: 개별 트리가 가질 수 있는 최대 리프 개수, LightGBM 복잡도 제어하는 주요 파라미터
- num_leaves 수를 높이면 정확도가 높아짐 ↔️ 트리 깊이 깊어지고 과적합 영향 커짐
- min_data_in_leaf: 사이킷런 래퍼 클래스에서 min_child_samples로 이름이 변경됨, 큰 값 설정시 트리가 깊어지는 것 방지
- max_depth: 명시적으로 깊이 제한
+) learning_rate을 작게, n_estimators를 크게 하는 부스팅 계열 튜닝 기본 방안을 적용하는 것도 좋음
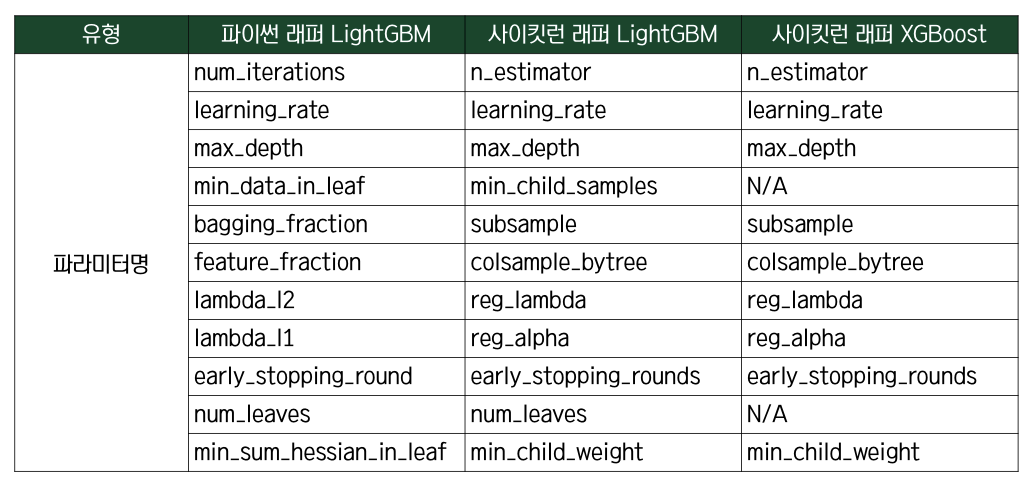
파이썬 래퍼 VS 사이킷런 래퍼 XGBoost LightGBM 하이퍼 파라미터 비교
파이썬 래퍼인지 사이킷런 래퍼인지에 따라 파라미터 명이 달라지는 경우가 많기 때문에 유의할 필요가 있음
!https://velog.velcdn.com/images/gchaewon/post/1a457681-a637-49f5-810d-7e16727ecdfa/image.png
{kind=link}
LightGBM - 사이킷런 LGBMClassifier 이용 학습 및 예측
fit()에 관련 파라미터를 설정해주면 조기 중단 가능
early_stopping_rounds 파라미터의 버전 오류가 있어서
lightgbm을 4.0.0 에서 3.3.2로 다운그레이드 진행
# lightgbm 다운그레이드
!pip uninstall lightgbm
!pip install lightgbm==3.3.2
이후 학습 및 예측 수행
# LightGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier 임포트
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
cancer_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
cancer_df['target']= dataset.target
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label, test_size=0.2, random_state=156 )
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train, test_size=0.1, random_state=156 )
# 앞서 XGBoost와 동일하게 n_estimators는 400 설정
lgbm_wrapper = LGBMClassifier(n_estimators=400, learning_rate=0.05)
# LightGBM도 XGBoost와 동일하게 조기 중단 수행 가능
evals = [(X_tr, y_tr), (X_val, y_val)]
lgbm_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric="logloss", eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1]
# 성능 평가
get_clf_eval(y_test, preds, pred_proba)
binary_logloss 점점 감소
61번 이후로 감소하지 않으므로 + 50번까지인 111번까지만 수행 후 조기 중단
XGBoost 보다 살짝 작지만, 데이터 세트 크기가 작으므로 알고리즘 간 큰 성능 차이가 없음
plot_importance() 로 피처 중요도 시각화
다른 사이킷런 래퍼 방식과 동일하므로 생략
'Python' 카테고리의 다른 글
| Home Credit Default Risk [1] feature engineering (0) | 2024.07.24 |
|---|---|
| 분류(Classification) - 3 베이지안 최적화와 고객만족예측 실습 (2) | 2024.07.23 |
| 분류(Classification) - 1 (0) | 2024.07.17 |
| 평가(Evaluation) (0) | 2024.07.17 |
| 사이킷런(scikit-learn)으로 시작하는 머신러닝 (0) | 2024.07.14 |